


本项目采用行人检测算法、行人跟踪算法、行人抓拍算法、行人量评分算法及行人识别算法、结合配套的前端摄像机设备和后端平台业务系统,实现了动态黑名单比对报警、静态人脸图片检索、大数据分析挖掘等功能。




 一、数据模块
一、数据模块
实现一个算法需要大量的数据,数据采集也称数据获取,是利用一种装置从系统外部采集数据并输入到系统内部的一个接口。常见的数据采集有视频数据采集、图像数据采集、文本数据采集和语音数据采集。对于本项目来说,我们需要的数据为视频和图片数据,因此数据采集流程为:
1、从大量的摄像设备中获取录制的视频文件
2、按照视频编解码技术对视频进行处理和抽帧,从而获得图片序列
3、利用检测和跟踪技术,选取每个目标序列的一张图像
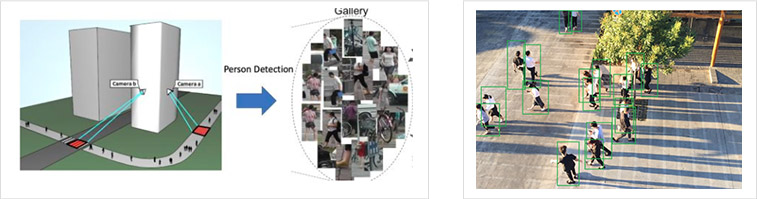
利用算法检测出的行人图像,仍然存在一些问题,因此需要人工进行清洗
1、图像模糊,清晰度导致80%的基本识别属性不能使用(基本识别属性:衣服颜色和类型、有无眼镜帽子、打电话、发型等。如果 图像模糊但是80%的基本属性不影响标注,需保留。否则删除)
2、图像截断(情况1:有完整的头部和上半身,情况2:除了头部,从肩到脚部分完整。这两种情况图像保留),否则删除图像
3、行人在图像的占比较小,行人占图像比例小于1/3
4、骑车、坐着、蹲着、弯腰90度的人删除
5、标注目标不唯一,图像中存在多个人,在标注属性时 不确定以哪个人作为“主目标”,则删除

(1) 确定要标注的属性,和每一种属性的具体类别信息,表中为本项目的行人属性和类别信息。
| 属性名称 | 具体类别 |
|---|---|
| 性别 | 1-男、0-女 |
| 年龄 | 0-未知、1-幼儿、2-少年(<16)、3-青年(17-30)、4-中年(30-60)、5-老年(>60) |
| 朝向 | 0-正向、1-侧身、2-背部 |
| 打伞 | 1-有打伞、0-无打伞 |
| 打电话 | 1-打电话、 0-不打电话 |
| 携带小孩 | 0-抱小孩、1-背小孩、2-未抱小孩 |
| 双肩包 | 0-无双肩包、1-有双肩包 |
| 单肩包 | 0-无单肩包、1-有单肩包 |
| 手提包 | 0-无手提包、1-有手提包 |
| 拉杆箱 | 0-无拉杆箱、1-有拉杆箱 |
| 发型 | 0-未知、1-短发、2-马尾、3-盘发、4-头部被遮挡、5-长发、6-光头 |
| 帽子 | 0-帽子、1-头盔、2-未戴帽子 |
| 眼镜 | 1-带眼睛、0-不带眼睛 |
| 围巾 | 1-带围巾、0-不带围巾 |
| 上衣类型 | 0-马甲吊带背心、1-衬衫、2-西服、3-毛衣、4-皮衣夹克、5-羽绒服、6-大衣风衣、7-连衣裙、8-T恤、9-无上衣、10-其它、11-帽衫 |
| 上衣颜色 | 0-黑、1-白、2-灰、3-绿、4-棕、5-红、6-黄、7-蓝、8-紫、9-混色、10-其他、11-深灰 |
| 上衣纹理 | 0-纯色、1-碎花、2-条纹、3-格子、4-文字、5-其他 |
| 下衣类型 | 0-长裤、1-七分裤、2-长裙、3-短裙、4-短裤、5-连衣裙、6-其他 |
| 下衣颜色 | 0-黑、1-白、2-灰、3-绿、4-棕、5-红、6-黄、7-蓝、8-紫、9-混色、10-其他、11-深灰 |
| 鞋子类型 | 0-未知、1-光脚,2-皮鞋、3-运动鞋、4-靴子、5-凉鞋、6-休闲鞋、7-其他 |
| 鞋子颜色 | 0-黑、1-白、2-灰、3-绿、4-棕、5-红、6-黄、7-蓝、8-紫、9-混色、10-其他、11-深灰 |
(2)制定标注的标准说明文档。在标注之前需要针对每一个属性制定一系列准则,以下内容摘自本项目的标准文档
一、性别
性别主要分:男、女、无效性别三部分
1、对于能够准确判断性别的,正常标注
2、“无效性别”
脸部被遮挡(被伞、树叶),被截断(图片中不存在人脸),难以判断性别。
如果图片清晰,标注人仍然无法判断男女,可标未知
3、如果被遮挡后 仍可以十分准确地判断出性别的,正常标注
二、发型
1、标未知:如果行人带帽子,或者头部露出一部分,但看不到发型
2、标头部遮挡:如果被伞、树叶或其他物体遮挡;图片中包含的行人没有头部,标为“头部被遮挡”
....

(3) 利用标注工具进行标注
数据标注通常都需要借助一定的标注工具,标注工具可以方便图像呈现和属性选择,一个好的标注工具能够加快标注的速度,并且拥有较高的标注正确率。针对本项目的任务,我们开发了一个行人属性标注工具,该工具可以选择指定路径下的图像文件,并逐张显示每张图像,标注人员可以在右边标注图像中的行人属性信息。每一张图像的标注结果将会保存在一个json文件中

标注后的json文件格式如下
{
"image_name": "000002.jpg",
"attr": [
{
"type": "gender",
"value": 0
},
{
"type": "age",
"value": 3
},
{
"type": "face",
"value": 0
},
{
"type": "hair",
"value": 5
},
.....
{
"type": "shoes_color",
"value": 0
}
]
}
二、图像处理模块
不同的识别技术依赖不同类型的特征(如听觉依赖声音特征、触觉依赖压觉特征),而基于视觉的识别技术则依赖于视觉特征。从物理角度解释,颜色产生于光源刺激视网膜的电磁波的谱能量分布,是图像重要的视觉性质之一。此外,生物对颜色的感觉还与诸多因素相关,如神经、心理和生理等因素,且比例关系复杂。为对颜色进行量化描述,首先需要对颜色特征进行建模。颜色空间是对色彩的组织方式,通过使用某个三维颜色空间中的一个可见光子集可包含某个色彩域的所有色彩。一般而言,任何一个色彩域都是颜色的某个完全子集,任何一个颜色空间都无法包含一个色彩域的所有颜色。常见的颜色空间有如下几种:
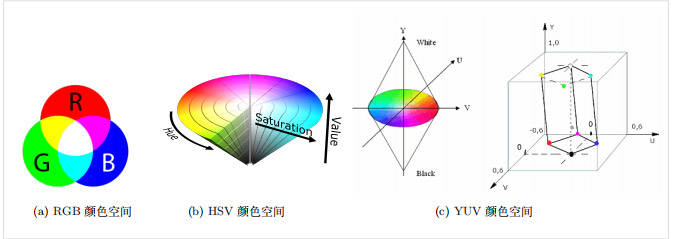
RGB:如图所示,RGB模型作为最常用的颜色空间之一,使用红(Red)、绿(Green)、蓝(Blue)三原色的亮度值来定量表示颜色。混色通过RGB三色光互相叠加来实现,因而该模型也称为加色混色模型,十分适合显示器等发光体颜色的显示。RGB颜色模型可以映射到三维直角坐标系中的一个正方体,这样任何RGB颜色空间中的一种颜色都可以使用三维空间中的一个点的坐标来表示。在RGB颜色空间中,当三个基色的亮度值都为零时,就显示为黑色;当三种基色都达到最高亮度时,就显示为白色;连接黑色与白色的对角线是三基色亮度值相等混合而成的灰色线。
HSV:HSV颜色空间中的每一种颜色都是由色相(Hue,简称H)、饱和度(Saturation,简称S)和色明度(Value,简称V)三个值表示。HSV模型对应于圆柱坐标系中的一个圆锥形子集,把颜色描述在圆柱坐标系内的点。如图\ref{fig:hsv_color_space}所示,圆锥的中心轴取值为自底部的黑色到中间的灰色,再到顶部的白色;绕中心轴的角度对应于“色相”,到这中心轴的距离对应于“饱和度”;沿着中心轴的高度对应于“明度”(或称之为“亮度”或“色调”)。HSV模型由埃尔维・雷・史密斯在1978年创立,它是三原色光RGB模型的一种非线性变换。
YUV:YUV:如图\ref{fig:yuv_color_space}所示,YUV模型产生于黑白电视到彩色电视的过渡时期,同样由三个分量组成。“Y”表示明亮度(Luminance或Luma),也就是灰度值;而“U”和“V” 则表示色度(Chrominance或Chroma),作用是描述影像色彩及饱和度,用于指定像素的颜色。彩色电视最早的构想是同时传输RGB三原色的数值,传输量是原来黑白带宽的3倍,这样传输量相对较多。为了便于编码、传输,并减少带宽占用和信息出错概率,同时考虑到人眼的视觉特点:对亮度更敏感、对位置和色彩相对不敏感,可以保存和传输更多的亮度信息,并减少色差信息的保存和传输。
YUV、YUV、YCbCr、YPbPr等专有名词都可称之为YUV。YUV的表示方法称为A:B:C表示法。大多数YUV格式使用的平均每像素位数都少于24位,主要的抽样(Subsample)格式有YCbCr 4:2:0、YCbCr 4:2:2、YCbCr 4:1:1和YCbCr 4:4:4。最常用Y:UV记录比重通常为1:1或2:1。
深度学习是由数据驱动的,数据的数量以及分布对模型的优劣起到决定性作用,所以需要对数据进行一定的预处理以及数据增强,用来提升模型的泛化能力。如果在训练过程中生成了与测试样本很相似的图片,那么模型的泛化能力自然可以得到提高。
图像左右翻转后,图像的基本信息不会影响,可以达到数据扩充的作用

class RandomHorizontalFlip(object):
"""Horizontally flip the image randomly with a given probability """
def __init__(self, probability=0.5):
self.probability = probability
def __call__(self, sample):
if np.random.uniform(0, 1) > self.probability:
return sample
else:
image = sample['image']
label = sample['label']
image = cv2.flip(image, 1)
return {'image': image, 'label': label}
图像旋转是可以模拟摄像机角度产生的问题,可以其到数据增广的作用。在OpenCV中旋转角度为θ是通过以下形式的变换矩阵实现的: $M = \begin{bmatrix} cos\theta & -sin\theta \ sin\theta & cos\theta \end{bmatrix}$
但是OpenCV提供了可缩放的旋转以及可调整的旋转中心,因此可以在自己喜欢的任何位置旋转。修改后的变换矩阵为
$\begin{bmatrix} \alpha & \beta & (1- \alpha ) \cdot center.x - \beta \cdot center.y \ - \beta & \alpha & \beta \cdot center.x + (1- \alpha ) \cdot center.y \end{bmatrix} $
其中:
$\begin{array}{l} \alpha = scale \cdot \cos \theta , \ \beta = scale \cdot \sin \theta \end{array} $,
为了找到此转换矩阵,OpenCV提供了一个函数cv.getRotationMatrix2D( 第一参数指定旋转圆点;第二个参数指定旋转角度;第二个参数指定缩放比例)。将图像相对于中心旋转45度而没有任何缩放比例。

class RandomHorizontalFlip(object):
"""rotate the image randomly with a given probability """
def __init__(self, probability=0.5):
self.probability = probability
def __call__(self, sample):
if np.random.uniform(0, 1) > self.probability:
return sample
else:
angles = np.random.uniform(-30, 30)
image = sample['image']
label = sample['label']
rows,cols, _ = image.shape
M = cv2.getRotationMatrix2D(((cols-1)/2.0,(rows-1)/2.0),angles,1)
image = cv2.warpAffine(image,M,(cols,rows))
return {'image': image, 'label': label}
在图像四周进行补充,从而保证目标信息在图像的中间区域,也是深度学习常用的数据增广方式之一

class Pad(object):
"""Pad the given Image on all sides with the given "pad" value."""
def __init__(self, padding, fill=0, padding_mode='constant'):
assert isinstance(padding, (numbers.Number, tuple))
assert isinstance(fill, (numbers.Number, str, tuple))
assert padding_mode in ['constant', 'edge', 'reflect', 'symmetric']
if isinstance(padding, Sequence) and len(padding) not in [2, 4]:
raise ValueError("Padding must be an int or a 2, or 4 element tuple, not a " +
"{} element tuple".format(len(padding)))
self.padding = padding
self.fill = fill
self.padding_mode = padding_mode
def __call__(self, img):
"""
Args:
img ( Image): Image to be padded.
Returns:
Image: Padded image.
"""
return F.pad(img, self.padding, self.fill, self.padding_mode)
def __repr__(self):
return self.__class__.__name__ + '(padding={0}, fill={1}, padding_mode={2})'.\
format(self.padding, self.fill, self.padding_mode)
改变图像亮度、色度等信息,可以用于模拟不同光照下的图像。

class ColorJitter(object):
"""Randomly change the brightness, contrast and saturation of an image."""
def __init__(self, probability=0.5):
self.probability = probability
def __call__(self, sample):
if np.random.uniform(0, 1) > self.probability:
return sample
else:
image = sample['image']
label = sample['label']
seq = iaa.Sequential([
# iaa.Fliplr(0.5),
iaa.Multiply((0.8, 1.2)),
iaa.Affine(
rotate=(-5, 5)
),
iaa.GaussianBlur(sigma=(0, 0.5)),
iaa.Sharpen((0.0, 1.0)),
iaa.WithColorspace(to_colorspace="HSV", from_colorspace="BGR",
children=iaa.WithChannels(1, iaa.Add(10)))
])
seq_det = seq.to_deterministic()
image_aug = seq_det.augment_images([image])[0]
return {'image': image_aug, 'label': label}
按照一定的概率随机对图像部分区域进行擦拭,以达到模拟目标被外界事物所遮挡的情况

class RandomErasing(object):
def __init__(self, probability=0.5, sl=0.04, sh=0.05,
mean=[0.4914, 0.4822, 0.4465]):
self.probability = probability
self.mean = mean
self.sl = sl
self.sh = sh
def __call__(self, sample):
if np.random.uniform(0, 1) > self.probability:
return sample
else:
target_area = np.random.uniform(self.sl, self.sh)
img = sample['image']
label = sample['label']
h = int(target_area * img.shape[0])
w = int(target_area * img.shape[1])
if w < img.shape[1] and h < img.shape[0]:
x1 = np.random.randint(0, img.shape[0] - h)
y1 = np.random.randint(0, img.shape[1] - w)
if img.shape[2] == 3:
img[x1:x1 + h, y1:y1 + w, 0] = self.mean[0]
img[x1:x1 + h, y1:y1 + w, 1] = self.mean[1]
img[x1:x1 + h, y1:y1 + w, 2] = self.mean[2]
else:
img[x1:x1 + h, y1:y1 + w, 0] = self.mean[1]
return {'image': img, 'label': label}
除了以上操作, 本项目还用大量的数据增强处理,共有10余种图像变换方式可以选择,包括数据缩放、标准化处理,加噪声、放射变化等等
三、图像分批
深度学习模型实际进行训练时,不是将所有样本一次性放入网络中进行训练。因为样本数量通常是以万、十万、百万位单位的,一次性读取需要大量的时间和内存消耗。因此,在深度学习训练时使用的方法是将数据拆分为多组,一般称为分批(batch)。在每次迭代训练时,读取一个batch的数据,然后不断重复以下过程:前向传播预测结果、通过损失函数计算误差、误差反向传播计算梯度、优化器更新误差梯度,直到所有batch都遍历完成
本项目使用pytorch中的torch.utils.data中Dataloader类,该类可以将数据集组织为batch的形式,并形成可迭代的数据装载器
DataLoader(dataset,
batch_size=1,
shuffle=False,
sampler=None,
batch_sampler=None,
num_workers=0,
collate_fn=None,
pin_memory=False,
drop_last=False,
timeout=0,
worker_init_fn=None,
multiprocessing_context=None)
从上面的代码中可以看到, Dataloader 的参数非常多,共有11个参数,但常用的就是下面五个:
dataset : Dataset 类,决定数据从哪里读取及如何读取
batchsize :批大小,每批有多少个样本
num_works :是否多进程读取数据,进程数目为2,表示2个进程。默认是1
shuffle :每个epoch中数据是否乱序
drop_last :当样本总数不能被batchsize整除时,是否舍弃最后一批数据
# 本项目数据模块(包含数据增强和数据分批)
def data_init():
root_path = args.data
json_path = args.json
train_txt = json_path + 'train/train_shuf.list'
val_txt = json_path + 'test/test.list'
normalizer = Normalize(mean=[0.485, 0.456, 0.406],
std=[0.229, 0.224, 0.225])
transform_train = transforms.Compose([
Rescale(224),
# RandomCrop(args.load_size),
RandomHorizontalFlip(),
ColorJitter(brightness=0.5),
Augmentation(),
ToTensor(),
normalizer,
# RandomErasing(),
])
dset_train = mix_data_json(root_path=root_path,
txt_path=train_txt,
no_json=False,
transform=transform_train)
loader_train = torch.utils.data.DataLoader(dset_train, batch_size=args.batch_size,
shuffle=False, num_workers=args.workers,
drop_last=True)
dset_val = mix_data_json(root_path=root_path,
txt_path=val_txt,
no_json=False,
transform=transforms.Compose([
Rescale(args.load_size),
ToTensor(),
normalizer
]))
loader_val = torch.utils.data.DataLoader(dset_val, batch_size=args.batch_size,
shuffle=False, num_workers=args.workers,
drop_last=False)
return loader_train, loader_val
四、数学模块
深度学习需要一系列数学科目,比如微积分、线性代数、概率论、复变函数、数值计算、优化理论、信息论等等。这些数学知识有相关性,但实际上按照这样的知识范围来学习,学习成本会很久,而且会很枯燥。本项目选择一些重要的、极其相关的数学知识
标量(scalar)是一个数,只有大小没有方向,用小写字母表示(如a)。
向量(vector)是一组有序排列的数,既有大小也有方向,用小写字母黑体表示(如x)
矩阵(matrix) 是一组相同维度的向量的集合,即二维数组,用大写字母黑体表示(如X)
张量(tensor) 当数组维度大于二维是,统一称为张量
标量、向量、矩阵是张量的特殊形式,当张量的维度是0、1、2时,我们分别称为标量、向量和矩阵。
向量和矩阵表示形式为

设$\boldsymbol{A}$是$n$阶方阵,如果数$\lambda$和$n$维非零列向量$\boldsymbol{x}$使关系式$\boldsymbol{Ax}=\lambda \boldsymbol{x}$成立,那么这样的数$\lambda$称为矩阵$\boldsymbol{A}$的特征值,非零向量$\boldsymbol{x}$称为$\boldsymbol{A}$对应于特征值$\lambda$的特征向量。式$\boldsymbol{Ax}=\lambda \boldsymbol{x}$也可写成$(\boldsymbol{A}-\lambda \boldsymbol{E})\boldsymbol{x}=\boldsymbol{0}$。这是$n$个未知数$n$个方程的齐次线性方程组,它有非零解的充分必要条件是系数矩阵行列式$|\boldsymbol{A}-\lambda \boldsymbol{E}|=\boldsymbol{0}$,等式左边可以整理成如下关于特征值$\lambda$的多项式

特征降维中的方法,如奇异值分解(Singular Value Decomposition,简称SVD)、主成分分析(Principal Component Analysis,简称PCA)和线性判别法(Linear Discriminant Analysis,简称LDA)等方法,都涉及到特征值和特征向量的计算。
$n$阶方阵$\boldsymbol{A}$中,主对角线上各个元素的总和被称为矩阵$\boldsymbol{A}$的迹,记作$tr(\boldsymbol{A})$。
线性变换是在两个向量空间(包括由函数构成的抽象向量空间)之间的一种保持向量加法和标量乘法的特殊映射。线性变换要满足如下性质: 对于实数域上的$n$维和$m$维线性空间$\boldsymbol{V_n}$和$\boldsymbol{U_m}$,$T$是一个从$\boldsymbol{V_n}$到$\boldsymbol{U_m}$的变换,有 (1) $\forall \boldsymbol{\alpha_1}, \boldsymbol{\alpha_2}\in \boldsymbol{V_n}$,都有$T(\boldsymbol{\alpha_1}+\boldsymbol{\alpha_2})=T(\boldsymbol{\alpha_1})+T(\boldsymbol{\alpha_2})$; (2) $\forall \boldsymbol{\alpha}\in \boldsymbol{V_n}, k\in \R$,都有$T(k\boldsymbol{\alpha})=kT(\boldsymbol{\alpha})$。 我们称$T$为从$\boldsymbol{V_n}$到$\boldsymbol{U_m}$的线性变换。 这里介绍几个常见的线性变换:
投影变换 投影是从向量空间映射到自身的一种线性变换$P$,满足$P^{2}=P$,也就是说,当$P$两次作用于某个向量,与作用一次得到的结果相同。比如说一束光打在一个正方体上,在桌面上形成一个影子,那么影子与正方体之间就相当于存在一个线性变换,三维到二维的线性变换。
正交变换
对于一个由空间$\R^n$投射到同一空间$\R^n$的线性转换,如果转换后的向量长度与转换前的长度相同,则为正交变换。
其中$|\boldsymbol{x}|$在空间$\R^n$内,$n$表示维度。
旋转变换
正交变换$U$根据它的行列式是否等于1而分为旋转变换与反射变换。当$det(U)=1$时,是旋转变换; $det(U)=1$时,是反射变换。它们的几何意义是旋转变换不但保持两点的距离不变,而且还保持方向(保向)不变,而反射变换是一个逆向变换。
每个输出值的变化量与其相应的输入值的变化量之比不是常数的转换。常见的非线性激活函数如表1所示。

导数(derivative)代表了在自变量变化趋于无穷小的时候,函数值的变化与自变量的变化的比值。几何意义是这个点的切线。物理意义是该时刻的(瞬时)变化率。 注意:在一元函数中,只有一个自变量变动,也就是说只存在一个方向的变化率,这也就是为什么一元函数没有偏导数的原因。在物理学中有平均速度和瞬时速度之说。平均速度有
其中$v$表示平均速度,$s$表示路程,$t$表示时间。这个公式可以改写为
其中$\Delta s$表示两点之间的距离,而$\Delta t$表示走过这段距离需要花费的时间。当$\Delta t$趋向于0($\Delta t \to 0$)时,也就是时间变得很短时,平均速度也就变成了在$t_0$时刻的瞬时速度,表示成如下形式:
实际上,上式表示的是路程$s$关于时间$t$的函数在$t=t_0$处的导数。一般的,这样定义导数:如果平均变化率的极限存在,即有
则称此极限为函数 $y=f(x)$ 在点 $x_0$ 处的导数。记作 $f'(x_0)$ 或 $y'\vert{x=x_0}$ 或 $\frac{dy}{dx}\vert{x=x_0}$ 或 $\frac{df(x)}{dx}\vert_{x=x_0}$。
通俗地说,导数就是曲线在某一点切线的斜率。
既然谈到偏导数(partial derivative),那就至少涉及到两个自变量。以两个自变量为例,$z=f(x,y)$,从导数到偏导数,也就是从曲线来到了曲面。曲线上的一点,其切线只有一条。但是曲面上的一点,切线有无数条。而偏导数就是指多元函数沿着坐标轴的变化率。
注意:直观地说,偏导数也就是函数在某一点上沿坐标轴正方向的的变化率。
设函数$z=f(x,y)$在点$(x_0,y_0)$的领域内有定义,当$y=y_0$时,$z$可以看作关于$x$的一元函数$f(x,y_0)$,若该一元函数在$x=x_0$处可导,即有
函数的极限$A$存在。那么称$A$为函数$z=f(x,y)$在点$(x_0,y_0)$处关于自变量$x$的偏导数,记作$f_x(x_0,y_0)$或$\frac{\partial z}{\partial x}\vert{y=y_0}^{x=x_0}$或$\frac{\partial f}{\partial x}\vert{y=y_0}^{x=x_0}$或$z_x\vert_{y=y_0}^{x=x_0}$。
偏导数在求解时可以将另外一个变量看做常数,利用普通的求导方式求解,比如$z=3x^2+xy$关于$x$的偏导数就为$z_x=6x+y$,这个时候$y$相当于$x$的系数。
某点$(x_0,y_0)$处的偏导数的几何意义为曲面$z=f(x,y)$与面$x=x_0$或面$y=y_0$交线在$y=y_0$或$x=x_0$处切线的斜率。
导数和偏导没有本质区别,如果极限存在,都是当自变量的变化量趋于0时,函数值的变化量与自变量变化量比值的极限。
- 一元函数,一个$y$对应一个$x$,导数只有一个。
- 二元函数,一个$z$对应一个$x$和一个$y$,有两个导数:一个是$z$对$x$的导数,一个是$z$对$y$的导数,称之为偏导。
- 求偏导时要注意,对一个变量求导,则视另一个变量为常数,只对改变量求导,从而将偏导的求解转化成了一元函数的求导。
标量对向量($n$维向量)的偏导数:$\frac{\partial u}{\partial \boldsymbol{v}}=(\frac{\partial u}{\partial v_1},\frac{\partial u}{\partial v_2},\cdots,\frac{\partial u}{\partial v_n})^T$。
向量($m$维向量)对标量的偏导数:$\frac{\partial \boldsymbol{u}}{\partial v}=(\frac{\partial u_1}{\partial v},\frac{\partial u_2}{\partial v},\cdots,\frac{\partial u_m}{\partial v})^T$。
向量($m$维向量)对向量($n$维向量)的偏导数(雅可比矩阵,行优先):
如果为列优先,则为上面矩阵的转置
阵(m×n阶矩阵)对标量的偏导数:
通过如下举例来说明神经网络中的前向和反向传播过程。假设网络如下图所示,第一层是输入层,包含两个神经元$i1$、$i2$和偏置项$b1$;第二层是隐含层,包含两个神经元$h1$、$h2$和偏置项$b2$,第三层是输出$o1$、$o2$,每条线上标的$wi$是层与层之间连接的权重,激活函数使用sigmoid函数($\sigma(x)=(1+e^{-x})^{-1}$)。
首先对网络权重赋初值,并给定了输入数据和结果标签,其中 输入数据:i1=0.05,i2=0.10; 结果标签:o1=0.01,o2=0.99; 初始权重:w1=0.15,w2=0.20,w3=0.25,w4=0.30,w5=0.40,w6=0.45,w7=0.50,w8=0.55。 优化目标是对于输入数据i1和i2,使其输出更接近o1和o2
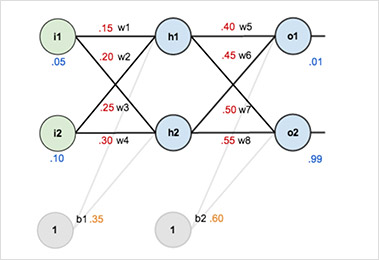
(1)进行前向传播
a、输入层$\rightarrow$隐含层: 计算神经元h1的输出值:
同理,可计算出神经元h2的输出值:
b、隐含层$\rightarrow$输出层: 按照同样方法计算神经元o1和o2的输出值:$out{o1}=0.75136507$,$out{o2}=0.772928465$。
通过这一次前向传播,可得到输出值为[0.75136079,0.772928465],与实际值[0.01,0.99]相差还很大,接下来对误差进行反向传播,更新权值,重新计算输出。
(2) 计算反向传播
a、计算总误差:
这里采用平方误差,总误差等于两个输出o1和o2的误差之和:
b、隐含层$\rightarrow$输出层的权值更新
以权重参数$w5$为例,如果想知道$w5$对整体误差产生了多少影响,可以用整体误差对$w5$求偏导求出:
下图直观地展示了链式法则
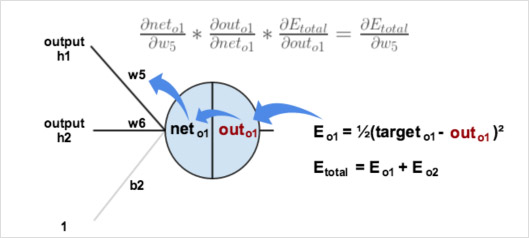
输出层到隐含层的误差传播与参数更新
现在分别计算每项偏导数,得到:
最后更新$w5$的值:
其中,$\eta$为学习率,这里取0.5。
同理,可更新$w6$,$w7$,$w8$:
隐含层$\rightarrow$隐含层的权值更新:
更新过程见图,根据前面的计算过程,我们可以计算得到总误差对$w1$的偏导。不同的是,隐含层节点$h1$会得到来自$o1$、$o2$两个节点的误差。
计算
最后,更新w1的权值
同理,可更新w2,w3,w4的权值:
至此就完成了一次误差的反向传播,现在再用更新后的权值重新计算新的输出值,可以计算得到总误差由0.298371109下降至0.291027924。如此重复迭代10000次后,总误差降到了0.000035085,输出值为[0.015912196,0.984065734],可以发现已经挺接近标签值[0.01,0.99]了
在概率论和统计学中,数学期望(或均值,亦简称期望)是试验中每次可能结果的概率乘以其结果的总和。它反映随机变量平均取值的大小。
线性运算: $E(ax+by+c) = aE(x)+bE(y)+c$
推广形式: $E(\sum{k=1}^{n}{a_ix_i+c}) = \sum{k=1}^{n}{a_iE(x_i)+c}$
函数期望:设$f(x)$为$x$的函数,则$f(x)$的期望为
注意:
- 函数的期望大于等于期望的函数(Jensen不等式),即$E(f(x))\geqslant f(E(x))$
- 一般情况下,乘积的期望不等于期望的乘积。
- 如果$X$和$Y$相互独立,则$E(xy)=E(x)E(y)$。
概率论中方差用来度量随机变量和其数学期望(即均值)之间的偏离程度。方差是一种特殊的期望。定义为:
方差性质:
1)$Var(x) = E(x^2) -E(x)^2$
2)常数的方差为0
3)方差不满足线性性质;
4)如果$X$和$Y$相互独立, $Var(ax+by)=a^2Var(x)+b^2Var(y)$
协方差是衡量两个变量线性相关性强度及变量尺度。 两个随机变量的协方差定义为:
方差是一种特殊的协方差。当$X=Y$时,$Cov(x,y)=Var(x)=Var(y)$。
协方差性质:
1)独立变量的协方差为0。
2)协方差计算公式:
3)特殊情况:
相关系数是研究变量之间线性相关程度的量。两个随机变量的相关系数定义为:
相关系数的性质:
1)有界性。相关系数的取值范围是 [-1,1],可以看成无量纲的协方差。
2)值越接近1,说明两个变量正相关性(线性)越强。越接近-1,说明负相关性越强,当为0时,表示两个变量没有相关性。
下面是 BN 算法在训练时的过程
输入:上一层输出结果 $ X = {x_1, x_2, ..., x_m} $,学习参数 $ \gamma, \beta $
算法流程:
其中,$ m $ 是此次训练样本 batch 的大小。
其中 $ \epsilon $ 是为了避免分母为 0 而加进去的接近于 0 的很小值
其中,$ \gamma, \beta $ 为可学习参数。
注:上述是 BN 训练时的过程,但是当在投入使用时,往往只是输入一个样本,没有所谓的均值 $ \mu{\beta} $ 和标准差 $ \sigma{\beta}^2 $。此时,均值 $ \mu{\beta} $ 是计算所有 batch $ \mu{\beta} $ 值的平均值得到,标准差 $ \sigma{\beta}^2 $ 采用每个batch $ \sigma{\beta}^2 $ 的无偏估计得到。
五、网络结构
卷积层(Convolution Layer)通常用作对输入层输入数据进行特征提取,通过卷积核矩阵对原始数据中隐含关联性的一种抽象。卷积操作原理上其实是对两张像素矩阵进行点乘求和的数学操作,其中一个矩阵为输入的数据矩阵,另一个矩阵则为卷积核(滤波器或特征矩阵),求得的结果表示为原始图像中提取的特定局部特征。图5.1表示卷积操作过程中的不同填充策略,上半部分采用零填充,下半部分采用有效卷积(舍弃不能完整运算的边缘部分)。
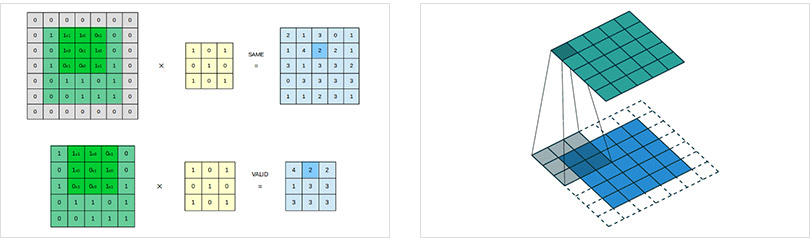
卷积的构建
nn.Conv2d(in_channels,
out_channels,
kernel_size,
stride=1,
padding=0,
dilation=1,
groups=1,
bias=True,
padding_mode='zeros')
功能:对多个二维信号进行二维卷积
主要参数:
| 参数名称 | 说明 |
|---|---|
| in_channels | 输入通道数 |
| out_channels | 输出通道数,等价于卷积核个数 |
| kernel_size | 卷积核尺寸 |
| stride | 步长 |
| padding | 填充个数 |
池化层又称为降采样层(Downsampling Layer),作用是对感受域内的特征进行筛选,提取区域内最具代表性的特征,能够有效地降低输出特征尺度,进而减少模型所需要的参数量。按操作类型通常分为最大池化(Max Pooling)、平均池化(Average Pooling)和求和池化(Sum Pooling),它们分别提取感受域内最大、平均与总和的特征值作为输出,最常用的是最大池化。
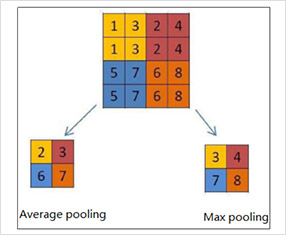
池化的构建
最大池化
nn.MaxPool2d(kernel_size,
stride=None,
padding=0,
dilation=1,
return_indices=False,
ceil_mode=False)
功能:对二维信号(图像)进行最大值池化
主要参数:
| 参数名称 | 说明 |
|---|---|
| kernel_size | 卷积核尺寸 |
| stride | 步长 |
| Padding | 补边的像素数目 |
| dilation | 池化核间隔大小 |
| ceil_mode | 尺寸向上取整 |
| return_indices | 记录池化像素索引 |
平均池化
nn.AvgPool2d(kernel_size,
stride=None,
padding=0,
ceil_mode=False,
count_include_pad=True,
divisor_override=None)
功能:对二维信号(图像)进行平均值池化
主要参数:
| 参数名称 | 说明 |
|---|---|
| kernel_size | 卷积核尺寸 |
| stride | 步长 |
| padding | 填充个数 |
| dilation | 池化核间隔大小 |
| ceil_mode | 尺寸向上取整 |
| countincludepad | 填充值用于计算 |
| divisor_override | 除法因子 |
全连接层(Full Connected Layer)负责对卷积神经网络学习提取到的特征进行汇总,将多维的特征输入映射为二维的特征输出,高位表示样本批次,低位常常对应任务目标。
nn.Linear(in_features, out_features, bias=True)
对一维信号(向量)进行线性组合
主要参数:
| 参数名称 | 说明 |
|---|---|
| in_features | 输入结点数 |
| out_features | 输出结点数 |
| Bias | 是否需要偏置 |
激活层(Activation Layer)负责对卷积层抽取的特征进行激活,由于卷积操作是由输入矩阵与卷积核矩阵进行相差的线性变化关系,需要激活层对其进行非线性的映射。激活层主要由激活函数组成,即在卷积层输出结果的基础上嵌套一个非线性函数,让输出的特征图具有非线性关系。卷积网络中通常采用ReLU来充当激活函数(还包括tanh和sigmoid等)ReLU的函数形式如公式(5-1)所示,能够限制小于0的值为0,同时大于等于0的值保持不变。
常用的激活函数
nn.Sigmoid()
nn.tanh()
nn.ReLU()
nn.LeakyReLU()
nn.PReLU()
nn.RReLU()
卷积神经网络(Convolutional Neural Networks,简称CNN)是一种常用的前馈神经网络,通过一系列卷积层和子采样层(也叫做池化层)来对输入数据进行特征抽取。在卷积操作中,卷积核只关注一个局部区域(即一个神经元只与部分前一层神经元连接),这个局部区域通常是二维或者三维的,使得卷积神经网络更适合处理图像视频数据。在对整个输入进行特征计算时,通过滑动卷积核实现参数共享,大大减少了参数量,这同时也使得卷积神经网络具有平移不变性。
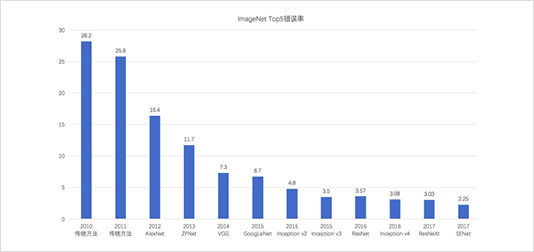
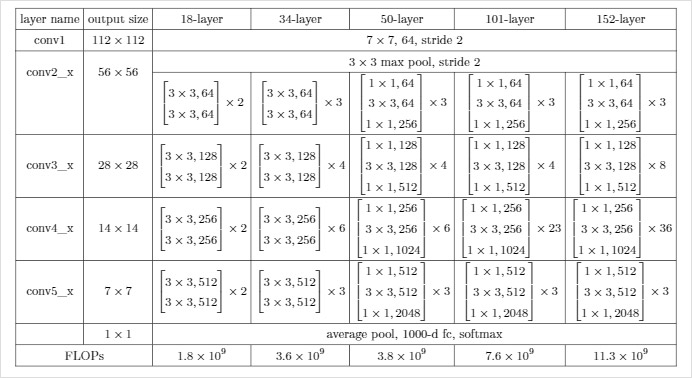
早期对于卷积神经网络的研究开始于二十世纪80至90年代,LeNet-5是最早出现的卷积神经网络;在二十一世纪后,随着深度学习理论的提出和数值计算设备的改进,卷积神经网络取得了很大的性能提升,在计算机视觉、自然语言处理等领域都得到了很好的应用。各个网络在ImageNet上的Top5准确率总结表如下图,可以看到ImageNet上的分类错误率逐年降低,并且已经低于人类的错误率(5.1%)。
LeNet-5作为最早的卷积神经网络,用来进行手写数字识别。与现在的网络相比虽然显得比较简单,但是它包含了卷积神经网络的基本模块:卷积层、池化层、全链接层,奠定了卷积神经网络的基础。网络通过巧妙的设计,利用卷积、参数共享、池化等操作提取特征,避免了大量的计算成本,之后采用全连接神经网络对提取到的特征进行分类识别。
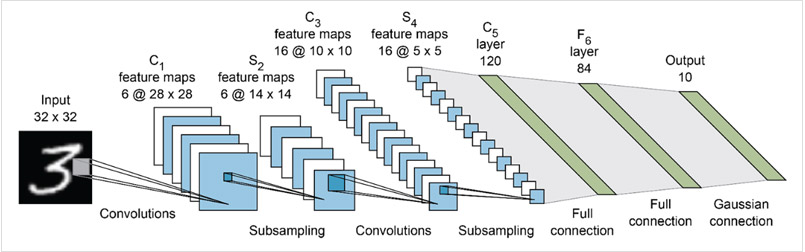
在2010年ImageNet LSVRC竞赛中以碾压性的优势胜取得了冠军,并得到了广泛关注。AlexNet相比于LeNet-5采用了更深的网络结构,并通过双GPU并行计算(每个GPU负责一半的运算处理,并规定GPU只在特定的层上进行通信交流)来提高运行速度和网络运行规模。为防止过拟合,采用了数据扩张、Dropout的策略。另外,用ReLU替代了tanh、sigmoid激活函数,加快了训练速度。
!
该网络的主要工作是验证了加深网络能在一定程度上提升网络的性能。该网络通过连续堆叠$3\times3$的卷积核来达到增大感受野的目的,相比于直接使用更大尺寸的卷积核($5\times5$、$7\times7$),这样做可以节省很多参数,从而保证网络能够有更深的深度。而这也使得VGG网络在2014年ImageNet LSVRC竞赛中取得了分类项目第二名、定位项目第一名的成绩,时至今日VGG网络也依然被用于提取图像特征。下图列出了不同深度的VGG网络结构,深度从11层到19层不等,比较常用的是VGGNet-16和VGGNet-19。VGG网络的卷积层可以分成五部分,每部分通过不同数量的$3\times3$、$1\times1$卷积核堆叠组成,并在每部分之后接一个最大池化层;卷积层后面是3个全连接层和一个softmax层进行分类。
!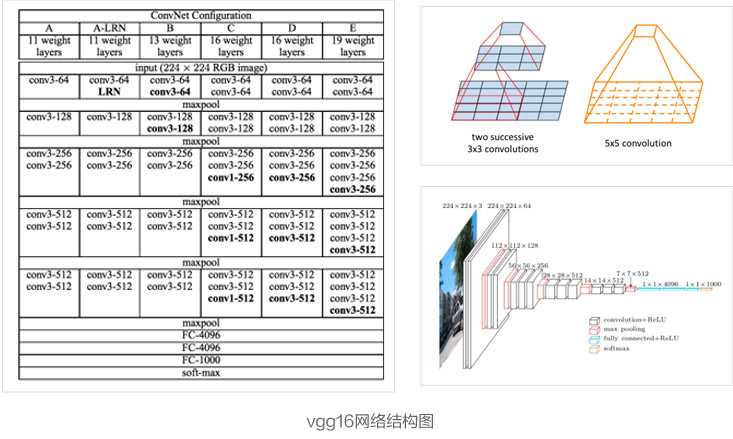
VGG网络的作者指出,在训练网络的时候,先训练简单的A网络,再用A网络的权重来初始化后面的几个复杂模型,可以达到更快的收敛速度。另外,作者说明了局部响应归一化层(LRN)作用不大,越深的网络效果越好,1×1的卷积也是很有效的,但是没有3×3的卷积效果好,因为3×3的卷积有更大的感受野。
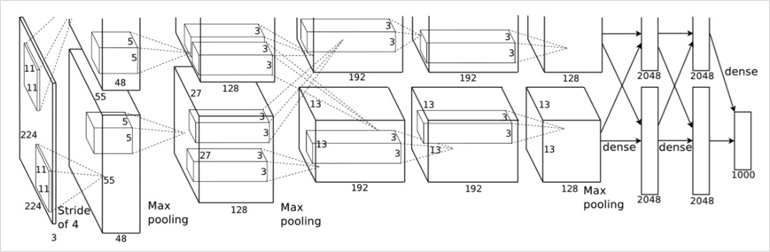
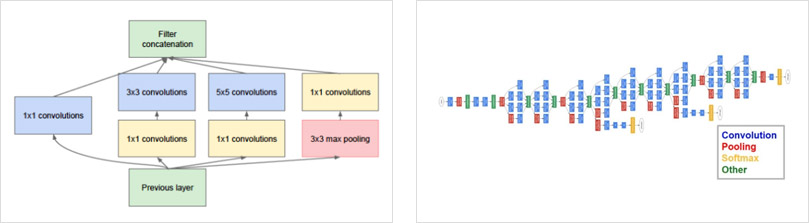
GoogLeNet作为2014年ILSVRC在分类任务上的冠军,以6.65%的错误率力压VGGNet等模型,在分类的准确率上面相比过去冠军有很大的提升。从名字GoogLeNet可以知道这是来自谷歌工程师所设计的网络结构,而名字中GoogLeNet更是致敬了LeNet。GoogLeNet中最核心的部分是其内部子网络结构Inception,至今已经经历了四次版本迭代。一层一层卷积堆叠,VGG是集大成者,但是之后很难再进一步,继续简单增加网络层数会遇到问题,更深的网络更难训练同时参数量也在不断增长。GoogLeNet则从另一个维度来增加网络能力,每单元有许多层并行计算,让网络更宽了,基本单元如下
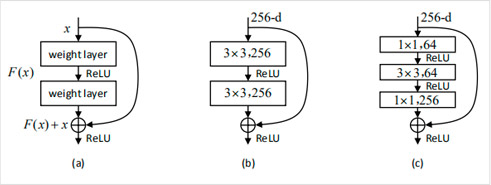
之前的网络验证了加深网络可以提升网络的性能,但是随着网络越来越深,相关研究者发现网络会出现退化现象(训练集准确率下降),并且可以排除这种退化现象是由于过拟合造成的(过拟合现象应该是在训练集上有很高的准确率)。针对这个问题,何恺明等人认为如果一个网络可以很容易地实现网络层之间的恒等映射(这里恒等映射即网络层输入与输出相等),那么一个更深的网络就应该比较浅的网络性能更好。但是直接使网络学到$F(x)=x$这种恒等映射比较困难,这也是深层网络出现退化的原因。因此何恺明等人提出了深度残差网络ResNet,网络实现了$H(x)=F(x)+x$这种残差连接,网络通过学习$F(x)=0$便能实现恒等映射,这比直接学习$F(x)=x$要相对容易很多。这就使得ResNet网络层数可以达到很深,而且即便是最深的ResNet-152的参数量也比VGG-16少。ResNet也在2015年ImageNet LSVRC竞赛中取得了分类、定位、检测三项冠军,以及2015年COCO竞赛中检测和分割任务的第一名。
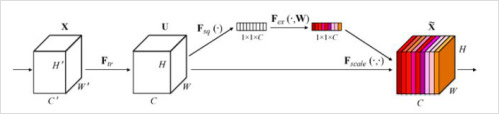
最后一届ImageNet的冠军算法是SENet,该算法认为不是每个通道都是一样重要,不同的通道重要性不同,应该赋予不同的权重。因此提出了SE模块。SENet的Squeeze-Excitation模块在普通的卷积(单层卷积或复合卷积)由输入X得到输出U以后,对U的每个通道进行全局平均池化得到通道描述子(Squeeze),再利用两层FC得到每个通道的权重值,对U按通道进行重新加权得到最终输出(Excitation),这个过程称之为feature recalibration,通过引入attention重新加权,可以得到抑制无效特征,提升有效特征的权重,并很容易地和现有网络结合,提升现有网络性能,而计算量不会增加太多。
SeNet网络主要优势
行人属性识别算法整体上可以分为3种类型,基于全局的、基于局部的、基于attention的行人属性算法,都是该领域提出的并在公开数据集上获得较好的效果的算法。最简单最直观的行人属性识别算法是基于全局的,其训练流程为:将整个行人图像作为输入,经过深度神经网络直接提取特征,之后输出一组对应的属性值,最后进行Loss计算和梯度反向传播,该类方法为基于全局的行人属性识别方法。之后有研究者认为一些属性和局部区域位置有关系,比如头肩区域负责识别发型、眼睛、口罩等属性,下半身区域负责裤子和鞋子属性。因此一些算法提取行人全局和局部的特征,从而预测对应的属性值,该类算法为基于局部的行人属性识别方法。2014年google mind团队利用Attention进行图像分类,并取得了优异的识别结果。基于attention的方法可以自动学习出与对应属性密切相关的特征或区域,之后出现了许多基于attention的行人属性识别方法。本项目对这些优秀的算法进行重现和优化,共使用了4个行人属性算法,其中基于attention的有两种不同的实现。之后再部署环节,可以根据实际场景以及服务器的类型选择一个算法进行预测,或多个算法集成式预测。接下来对这四种行人属性识别方法进行详细介绍。
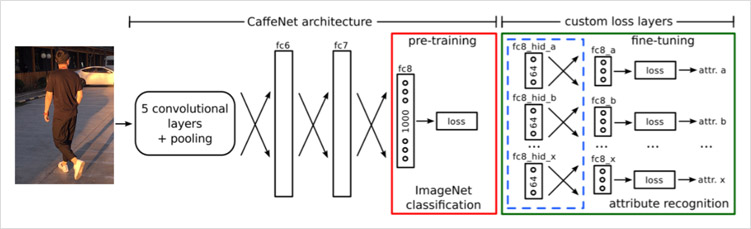
基于全局的行人属性识别算法是最简单、直观、易应用到实际中的方法,即输入为整个行人图像,然后对整体进行特征提取,并预测属性值。根据提取特征和优化方式的不同,研究者提出了许多不同的识别算法。行人图像的特征提取网络可以使用各种经典的或最新的网络结构,在优化时可以选择不同的优化方法、不同的损失函数,并且还可以对损失函数增加策略,比如将各个类别的损失值进行加权以解决数据不均衡的问题。本部分算法将整个行人图像作为输入,使用基准网络pre-tuning 作为特征提取子网络,并将最后的全连接层修改为多个并行的分类层和多个KL-loss层,是一个多分支的结构。
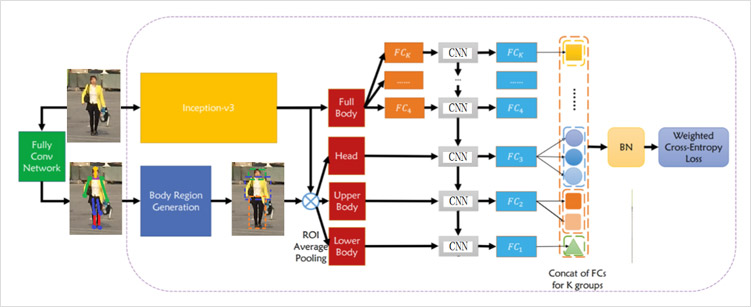
基于局部的识别方法除了考虑行人的整体信息,也结合图像的局部信息。实现流程可以为:
(1) 利用局部检测器、人体姿态关键点算法得到人体不同局部图(头肩区域、上半身区域、下半身区域)
(2) 将全身图像、头肩图像、上半身图像、下半身图像分别送入各自的网络结构
(3)使用头肩区域预测发型、帽子、围巾等属性,使用上半身区域预测上衣颜色、上衣纹理等属性,使用下半身区域预测裤子、裙子、鞋子等信息;使用全身图像预测性别、背包等属性
(4)将负责各个区域的网络预测结果进行合并,从而得到行人图像的全部属性信息
!
Attention机制是模拟生物观察行为的内部过程,将有限的注意力资源用于从大量的信息中快速筛选出高价值信息。比如,当人的视觉观察一张照片时,首先快速扫面全局图像,然后重点关注部分区域(也就是注意力焦点),发现极具判别性的信息,从而得出正确的识别结果。目前被广泛应用于图像识别、自然语言处理和语音识别领域。
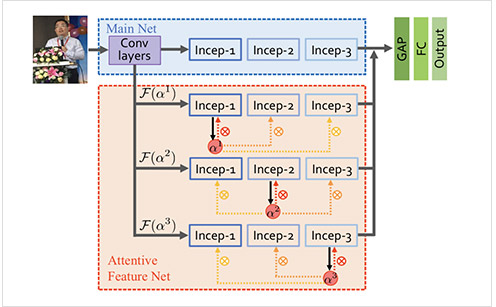
本项目也将Attention机制应用到行人属性识别中,借鉴HydraPlus算法。该算法之所以命名为Hydraplus是因为其中的AF网络(Attention Feature Net)包含9部分。该算法是一个分阶段的网络结构,能够从低层次到语义层次捕获多个注意力,并将不同层级的注意力映射到不同的特征层,丰富了行人图像的最终特征。该算法提出的同时公开了PA100K数据集,并在PA100K上获得优异的识别结果。HydraPlus的结构如图所示,主要包括一个主网络和一个AF-net,将主网络和AF-net获得的特征进行融合,然后通过GAP、FC层处理,从而得到最终的行人图像特征。Hydra-plus训练过程为:
训练主网络,使用inception结构
训练AF网络,包括三个MDA(multi-directional attention)模块,可表示为AF-1、AF-2、AF-3
以AF-1的训练为例说明如何训练AF子网络,
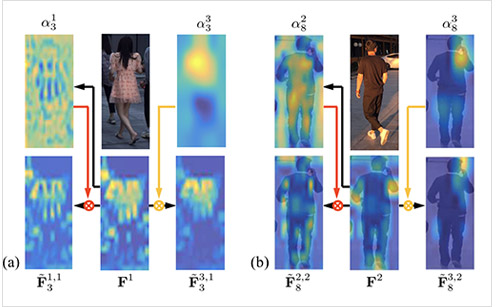
Incep-1、Incep-2、Incep-3分别是图像不同层次的特征信息,Incep-1表示浅层特征,可以用于识别纹理和边缘信息,Incep-3表示语义级特征,可以用于语义级属性。如图所示,$a^1_3$表示Incep-1($F^1$)对应的attention map中的第3个特征图,$a^2_8$表示Incep-2($F^2$)对应的attention map中的第8个特征图。其中$a^1_3$和$F^1$结合可以得到中$\tilde{F}^{1,1}3$,$\tilde{F}^{1,1}3$可以用于识别衣服纹理,$\tilde{F}^{3,2}_8$可以检测出耳朵附件的电话,用于识别打电话属性。不同层级的attention和不同尺度的特征进行结合,可以用于表达不同属性,从而使对应的属性更加突出。但是该方法网络结构复杂,对应的时间和空间复杂度较高。
Vespa利用viewpoint(视角、方向)作为attention信息进行行人属性识别,作者认为属性预测和viewpoint有一定的依赖关系,并且view-sensitive的方式能够学习到更好的属性预测,该算法也是一个多任务学习算法,同时预测行人的viewpoint信息和其他属性信息。Vespa在网络结构中同时设置3个模块,分别代表正面、背面、侧面单元,并预测3组属性值,之后借助分类器(view predictor)的输出的结果将3组属性值进行融合,从而得到最终的属性预测结果。RAP数据中有视角的标注,因此在网络结构设计中引出一条分支利用该标注训练viewpoint分类器,网络结构如图所示
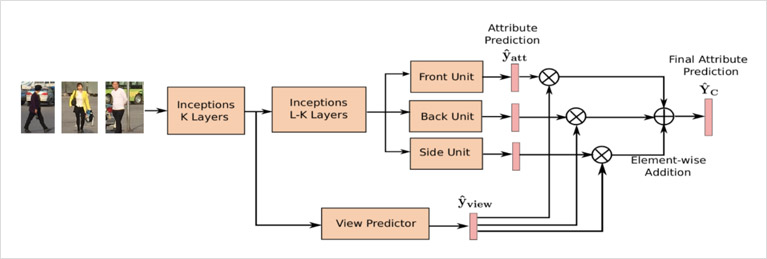
Vespa的的预测过程如下:
(1) 行人图像经过CNN进行特征提取,
(2) 在第K层之后经过viewpoint分类器对行人图像进行分类,接softmax层输出代表正、侧、后三个方位概率的值
(3) 在第K-l层之后通过代表3个方位的Inception模块,对所有属性进行预测
(4) 3个方向的概率值作为3个方位的预测结果的权重,最终的预测结果由3个分支的预测结果相加后接sigmoid层得出行人的view信息是行人属性识别的一部分,很多数据集都有标注view信息。该方法相对来说结构较为简单,易于实现,没有引入额外的标注信息,并且获得了优异的性能。
六、损失函数
损失函数:衡量模型输出与真实标签之间的差异
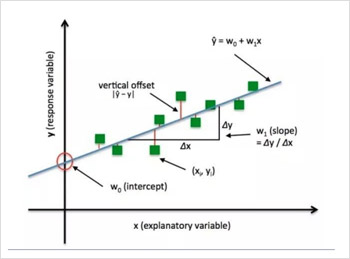
绿色的点为真实值、线为模型预测结果。差距越大表示误差越大;差距越小表示误差越小。对于一个深度学习的训练过程,可以将它描述为让模型输出值和实际值越来越接近的过程。因此需要一个函数能够评估预测结果和真实结果不一致程度,也就是所谓的损失函数。一个损失函数需要一对输入:模型输出和真实标签,然后计算一个值来评估输出距离目标有多远。
在实际使用中需要根据不同任务选择不同的损失函数,在pytorch中提供了18个损失函数。损失函数是评估真实值和预测值之间差异的一种方式,在pytorch将不同的损失函数定义为一个类,而不是一个函数。所有的损失函数都在torch.nn模块下。
1. nn.CrossEntropyLoss
2. nn.NLLLoss
3. nn.BCELoss
4. nn.BCEWithLogitsLoss
5. nn.L1Loss
6. nn.MSELoss
7. nn.SmoothL1Loss
8. nn.PoissonNLLLoss
9. nn.KLDivLoss
10. nn.MarginRankingLoss
11. nn.MultiLabelMarginLoss
12. nn.SoftMarginLoss
13. nn.MultiLabelSoftMarginLoss
14. nn.MultiMarginLoss
15. nn.TripletMarginLoss
16. nn.HingeEmbeddingLoss
17. nn.CosineEmbeddingLoss
18. nn.CTCLoss
下面重点介绍常用的交叉熵损失函数nn.CrossEntropyLoss
nn.CrossEntropyLoss(weight=None,
size_average=None,
ignore_index=-100,
reduce=None,
reduction='mean')
参数说明
| 参数名称 | 类型 | 说明 |
|---|---|---|
| weight | (Tensor, optional) | 自定义的每个类别的权重. 必须是一个长度为 C 的 Tensor(和类别数一致) |
| ignore_index | (int, optional) | 设置一个目标值, 该目标值会被忽略, 从而不会影响到 输入的梯度。 |
| reduction | none、mean、sum。默认:mean |
下图为softmax的计算过程

nn.CrossEntropyLoss的使用说明
# 预测值和真实值
outputs = torch.tensor([[1, 2], [1, 3], [1, 3]], dtype=torch.float)
target = torch.tensor([0, 1, 1], dtype=torch.long)
# 实例化损失对象
loss_f_none = nn.CrossEntropyLoss(weight=None, reduction='none')
loss_f_sum = nn.CrossEntropyLoss(weight=None, reduction='sum')
loss_f_mean = nn.CrossEntropyLoss(weight=None, reduction='mean')
# forward
loss_none = loss_f_none(outputs, target)
loss_sum = loss_f_sum(outputs, target)
loss_mean = loss_f_mean(outputs, target)
# view
print("Cross Entropy Loss:\n ", loss_none, loss_sum, loss_mean)
# Cross Entropy Loss:
# tensor([1.3133, 0.1269, 0.1269]) tensor(1.5671) tensor(0.5224)
当训练有 C 个类别的分类问题时很有效. 可选参数 weight 必须是一个1维 Tensor, 权重将被分配给各个类别. 对于不平衡的训练集非常有效。在多分类任务中,经常采用 softmax 激活函数+交叉熵损失函数,因为交叉熵描述了两个概率分布的差异,然而神经网络输出的是向量,并不是概率分布的形式。所以需要 softmax激活函数将一个向量进行“归一化”成概率分布的形式,再采用交叉熵损失函数计算 loss。
七、优化器(方式)
优化器主要是为了优化我们的神经网络的参数,优化器的选择影响着神经网络的训练时间和训练结果。优化器主要负责管理并更新模型中可学习参数的值,使得模型输出更接近真实值。可学习参数就是卷积、池化、全连接层的权值和偏置。在利用损失函数计算出误差值后,调用backward可以反向传播计算参数对误差值的梯度。之后需要利用一定的规则将参数更新沿着梯度下降的方向进行,最终使得loss值下降,这就是优化器的工作过程。在本项目中我们会对多中优化器进行学习对比,最终选择效果最好的优化器
1. optim.SGD:随机梯度下降法
2. optim.Adagrad:自适应学习率梯度下降法
3. optim.RMSprop: Adagrad的改进
4. optim.Adadelta: Adagrad的改进
5. optim.Adam:RMSprop结合Momentum
6. optim.Adamax:Adam增加学习率上限
7. optim.SparseAdam:稀疏版的Adam
8. optim.ASGD:随机平均梯度下降
9. optim.Rprop:弹性反向传播
10. optim.LBFGS:BFGS的改进
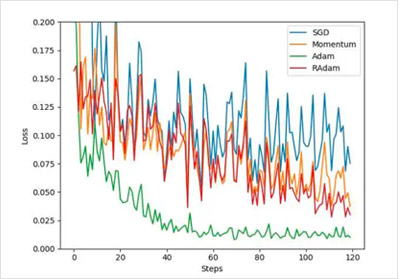
通常使用最多的就是SGD优化方法。Stochastic Gradient Descent (SGD) SGD是最基础的优化方法。普通的训练方法, 需要重复不断的把整套数据放入神经网络中训练, 这样消耗的计算资源会很大。当我们使用SGD会把数据拆分后再分批不断放入神经网络中计算. 每次使用批数据, 虽然不能反映整体数据的情况, 不过却很大程度上加速了神经网络的训练过程, 而且也不会丢失太多准确率
optim.SGD(params,
lr=<object object>,
momentum=0,
dampening=0,
weight_decay=0,
nesterov=False)
| 参数名称 | 说明 | 类型 |
|---|---|---|
| lr | 学习率 | float |
| momentum | 动量因子(默认:0,通常设置为0.9,0.8) | float |
| weight_decay | 权重衰减(L2惩罚)(默认:0) | float |
| dampening | 动量的抑制因子(默认:0) | float |
| nesterov | 使用Nesterov动量 | bool |
如何构建和使用优化器
在创建优化器对象的时候,要传入网络模型的参数,并设置学习率等优化方法的参数
optimizer = torch.optim.SGD(net.parameters(),lr = LR,momentum=0.8)
for epoch in range(epochs):
for input, target in train_data:
# 在每个batch训练过程中需要使用优化器进行参数更新
optimizer.zero_grad() # pytorch特性:张量梯度不自动清零,需要手动梯度清零
output=net(input)
loss = loss_fn(output,target)
loss.backward(loss)
optimizer.step() # 执行一步更新
优化器是在训练过程中进行调用的,更确切的是在某个epoch的一个batch数据处理过程中被调用。具体过程说明:
1、调用optimizer.zero_grad() 清空过往梯度;
2、将数据输入网络进行预测,并且获得loss
3、调用loss.backward() 反向传播,计算梯度;
4、调用optimizer.step() 根据梯度更新网络参数
在使用预训练模型时,需要为不同层设置不同的优化方式。本项目将前N层的学习设置的较少,后几层设置较大的学习率。从而达到在效果稳定的前提下,加快参数的更新幅度。
# 为不同子网络设置不同的学习率,在finetune中经常用到
# 如果对某个参数不指定学习率,就使用最外层的默认学习率
optimizer =optim.SGD([
{'params': net.features.parameters()}, # 学习率为1e-5
{'params': net.classifier.parameters(), 'lr': 1e-2}
], lr=1e-5)
# 逐轮进行
for epoch in range(MAX_EPOCH):
# 注意---------------------
net.train() # 表示开始训练
# 对训练集进行遍历,分批次处理
for i, data in enumerate(train_loader):
# data是每批的数据(返回值根据人民币对象RMBDataset的getitem)
# input 是图片数据; labels是标签,path_img是图像路径
inputs, labels, path_img = data
outputs = net(inputs) # 图像数据传入网络进行预测得到outputs
# 16行2列的数据
# 梯度清零(梯度回传之前需要清零)
optimizer.zero_grad()
# 根据预测值和真实值计算loss
# criterion是损失函数对象
loss = criterion(outputs, labels)
loss.backward() # loss反向传播,计算每个可学习参数的梯度
# update weights
optimizer.step() # 更新梯度 w= w-lr*grad
# 统计分类情况,计算准确率
# acc = 正确识别数目/总数目
九、评估算法
通常的单属性分类可以使用recall和accuracy进行评估。recall是正确识别的样本数目/该类样本的数目,accuracy是正确识别的样本数目/预测为该类的样本数目,分别反映了该类属性的查全率和查准率。但是行人属性是一个多属性多类别的任务,为了更好的反映一个算法的识别效果。因此,目前在行人属性识别领域中,主流的两种评估方法是:label-based和example-based
基于label的评估方法,主要关注每个label,对每个label进行统计度量,使用mean accuracy进行评估。
1、 计算每个属性的mean accuracy:分类计算每个属性正样本和负样本的accuracy,然后取平均。
2、计算整体的mean accuracy:将L个属性的mean accuracy的值进行评估
N是属性的类别数目,$TP_i$和$TN_i$是正确预测的正样本和负样本的数目,$P_i$和$N_i$是预测为正样本和负样本的数目
由于基于label的评估方法将单独计算每个属性,忽略了多属性识别任务中属性之间的关系。一些研究者针对该算法提出了基于example的评估方法,该方法可以更好地捕捉预测出的属性结果之间的相关性。它对每个样本进行评价,通过计算每个样本正确分类和错误分类之间的属性关系计算一组指标。包括Acc、precision、recall、F1。
其中N是样本数目,$Y_i$是第i个样本的ground truth positive label,$f(x_i)$是预测的positive label
十、模型保存
模型训练完成后通常需要进行保存,
python中网络结构和参数是分开的,可以分别保存、也可以一起保存
torch.save(object, path)
参数:object保存的数据;path保存的路径
当我们训练完成后,可以通过以下两种方法进行保存。推荐第二种
# 保存
path_model = "./model.pkl"
path_state_dict = "./model_state_dict.pkl"
# 保存整个模型:网络结构和参数
torch.save(net, path_model)
# 保存模型参数:保存网络中的参数, 速度快,占空间少
net_state_dict = net.state_dict()
torch.save(net_state_dict, path_state_dict)
# 加载
#1、加载网络结构和参数
path_model = "./model.pkl"
net_load = torch.load(path_model)
# 2、加载模型参数。需要自己定义网络网络,然后load模型参数字典
path_state_dict = "./model_state_dict.pkl"
state_dict_load = torch.load(path_state_dict)
net_new = LeNet2(classes=2019) #定义网络结构
net_new.load_state_dict(state_dict_load) # 将参数字典放入 新网络结构
实际任务中,训练一个模型时间较长,为了防止训练中因电脑异常导致中断。比如你要训练10个epoch,但是当训练第7个时候电脑关闭啦。为了下次能从第7次继续执行,需要在训练中保存一些信息:模型参数、优化器参数、第几个epoch等信息。
# 断点式保存和加载
for epoch in epochs:
"""
训练过程.....
"""
# 每2个epoch保存一次
if epoch % 2 == 0:
checkpoint = {"model_state_dict": net.state_dict(),
"optimizer_state_dict": optimizer.state_dict(),
"epoch": epoch}
path_checkpoint = "./checkpoint_{}_epoch.pkl".format(epoch)
torch.save(checkpoint, path_checkpoint)
path_checkpoint = "./checkpoint_7_epoch.pkl"
checkpoint = torch.load(path_checkpoint)
net.load_state_dict(checkpoint['model_state_dict'])
optimizer.load_state_dict(checkpoint['optimizer_state_dict'])
start_epoch = checkpoint['epoch']
# 开始训练---------------------
for epoch in range(start_epoch + 1, epochs):
"""
继续训练
"""
Copyright©1999- 北京中公教育科技有限公司 .All Rights Reserved 京ICP备10218183号-88
京ICP证161188号  京公网安备11010802020723号
京公网安备11010802020723号  投诉建议:400-650-7353
投诉建议:400-650-7353










 视频教程
视频教程

 项目简介
项目简介

 技术栈
技术栈

 环境配置
环境配置

 项目流程
项目流程
 项目应用--实践
项目应用--实践
 一、数据模块
一、数据模块 

