



互联网为用户提供了各种房源数据,在爬虫的爬取下集中有用的数据,可以为用户挖掘出隐藏在网络数据中所有的房源分布情况以及价格等走向,帮助用户做更好的决策。





 1、应用技术
1、应用技术
Scrapy是用纯Python实现的一个为了爬取网站数据、提取结构性数据而编写的应用框架,用途十分的广泛。
框架的力量,用户只需要定制开发几个模块就可以轻松实现一个爬虫,用来抓取网页内容以及各种图片,非常方便。Scrapy使用了Twisted异步网络框架来处理通讯,可以加快下载速度,其中包含了各种中间件接口,可以灵活完成各种需求。一下是Scrapy框架的架构图。
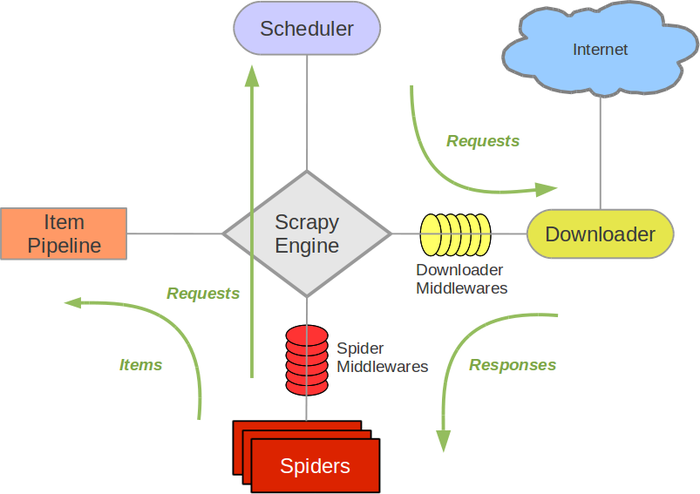
各组件作用如下:
Scrapy Engine(引擎):负责spider、ItemPipeline、Downloader、Scheduler中间的通讯,信号、数据传递等。
Scheduler(调度器):它负责接受引擎发送过来的Request请求,并按照一定的方式进行整理排列,入队,当引擎需要时,交还给引擎。
Downloader(下载器):负责下载Scrapy Engine(引擎)发送的所有Requests请求,并将其获取到的Responses交还给Scrapy Engine(引擎),由引擎交给spider来处理。spider(爬虫):它负责处理所有Responses,从中分析提取数据,获取Item字段需要的数据,并将需要跟进的URL提交给引擎,再次进入Scheduler(调度器)。
Item Pipeline(管道):它负责处理spider中获取到的Item,并进行后期处理(详细分析、过滤、存储等)。
Downloader Middlewares(下载中间件):你可以当作是一个可以自定义扩展下载功能的组件。
SpiderMiddlewares(spider中间件):你可以理解为是一个可以自定义扩展和操作引擎和spider中间通信的功能组件(比如进入spider的Response和从spider出去的Requests)。
Scrapy-Redis架构如下图所示:
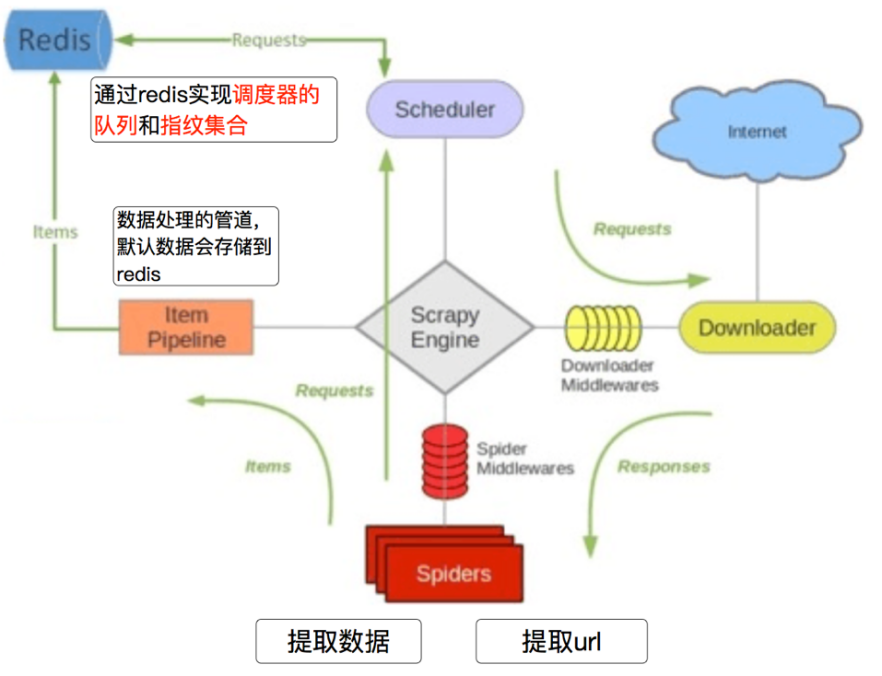
MongoDB 是一个基于分布式文件存储的数据库。由 C++ 语言编写。旨在为 WEB 应用提供可扩展的高性能数据存储解决方案。
MongoDB 是一个介于关系数据库和非关系数据库之间的产品,是非关系数据库当中功能最丰富,最像关系数据库的。
MongoDB 将数据存储为一个文档,数据结构由键值(key=>value)对组成。MongoDB 文档类似于 JSON 对象。字段值可以包含其他文档,数组及文档数组,如图下图所示:
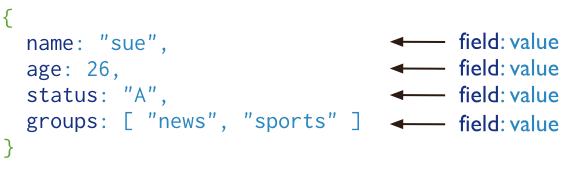
MongoDB数据库主要有特点如下:
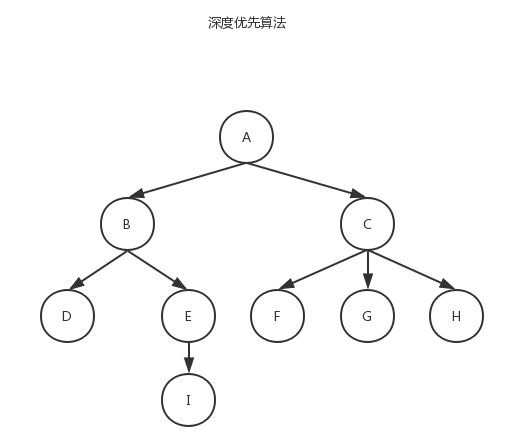
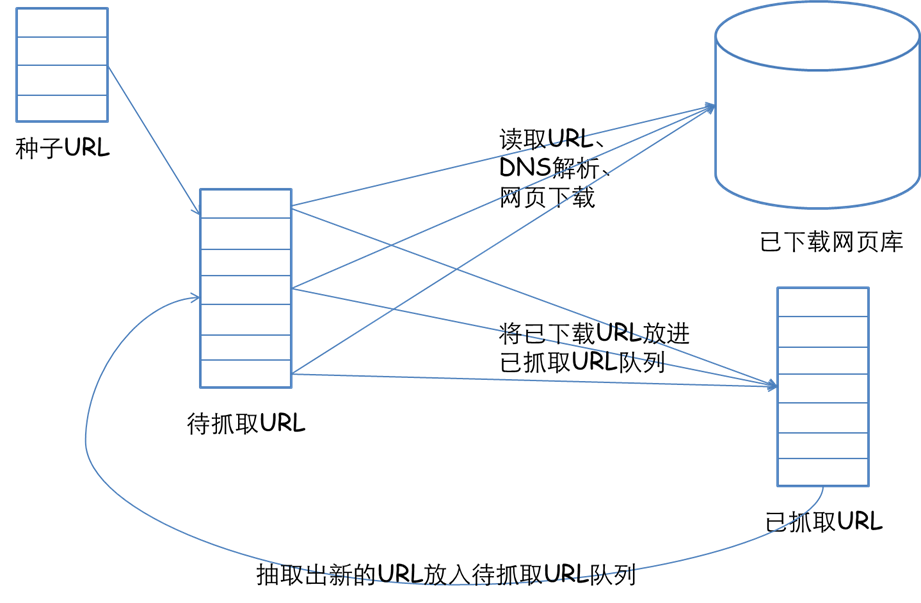
链家二手房数据的爬取使用深度优先搜索策略。
深度优先搜索是一种在开发爬虫早期使用较多的方法。它的目的是要达到被搜索结构的叶结点(即那些不包含任何超链的HTML文件) 。在一个HTML文件中,当一个超链被选择后,被链接的HTML文件将执行深度优先搜索,即在搜索其余的超链结果之前必须先完整地搜索单独的一条链。深度优先搜索沿着HTML文件上的超链走到不能再深入为止,然后返回到某一个HTML文件,再继续选择该HTML文件中的其他超链。当不再有其他超链可选择时,说明搜索已经结束。
2、整体框架结构
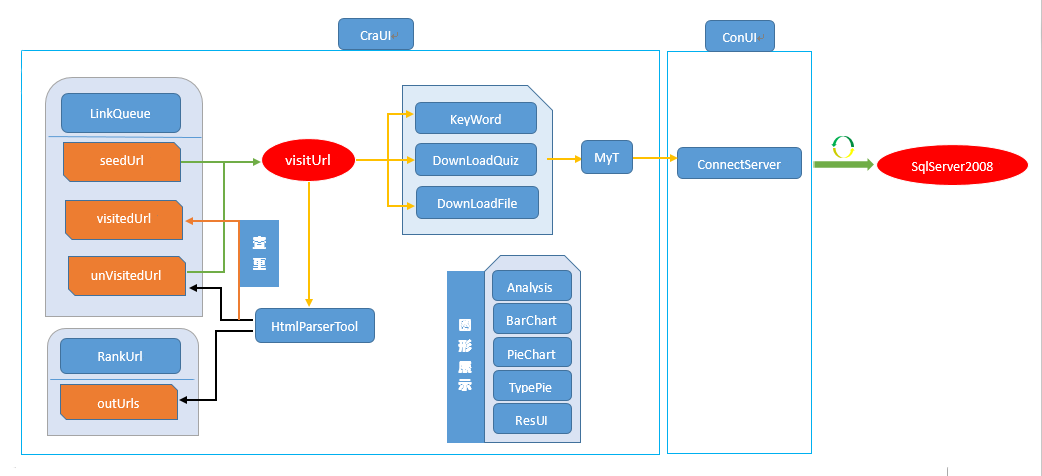
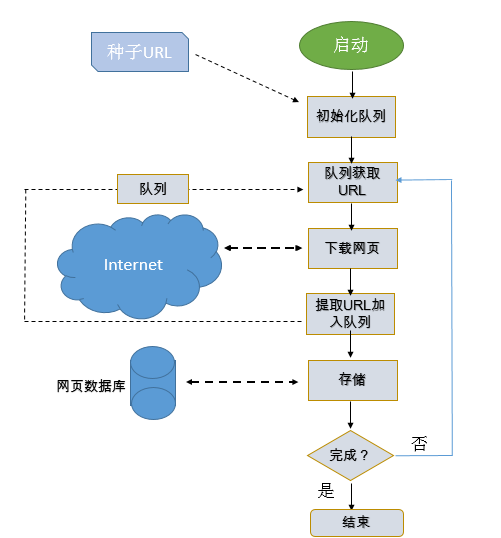
3、工作过程设计
根据两个框架图,可以进一步设计出爬虫的如下工作方式:
创建scrapy项目:scrapy startproject 项目名
创建爬虫文件:scrapy genspider 爬虫名 域名
将给定的初始URL加入到start_urls中,等待调度。
进入Items.py文件中,定义需要获取的字段。
回到爬虫文件,编写获取数据逻辑,取得所有所需数据。
进入Pipelines.py文件,编写保存数据方法。
将整个Scrapy项目改成Scrapy-Redis分布式,加快爬取速度,在对URL进行爬取的过程中,先使用Redis数据库中的集合对将要爬取的URL进行判重,如果返回值为0,代表爬取过,则不进行爬取,否则,会继续将URL存到调度器中,等待调度。










 视频教程
视频教程

 项目简介
项目简介

 环境配置
环境配置

 代码框架规范
代码框架规范

 整体架构
整体架构
 1、应用技术
1、应用技术