



本项目以房产数据分析进行介绍,包括数据采集、数据清洗和处理、数据分析和数据可视化等环节。





 (一) 数据集成
(一) 数据集成
数据集成(Data Integration)是数据处理的首要环节,即将不同数据源、数据文件、数据对象中的数据进行整合归纳,最终生成一个数据对象。对于房产数据来说,我们在获取数据时可能会按照区域、时间等特征将数据存储在多个文件源中。以本项目的上海房产为例,如果将浦东新区房产数据存储为一个文件,静安区房产数据存储为一个文件,每个区的房产数据都单独存放。那么我们拿到数据的第一步就要进行数据集成。
数据集成最基本的形式是数据源内容的上下合并或者左右合并,但是由于不同的数据源定义属性时命名规则不同,存入的数据格式、取值方式、单位都会有不同,并且不同属性字段可能会存在关联关系。因此在数据集成可以分为如下四种情况。
如果两个或多个数据源的属性信息是一致的,各自表示不同区域的房产数据,我们可以进行上下合并。
| 数据源1 | |||
|---|---|---|---|
| 房产编号 | 小区 | 房屋户型 | 建筑面积 |
| SH001 | 江临天下 | 4室2厅1厨2卫 | 165.73 |
| SH002 | 樱花路309弄 | 2室2厅1厨1卫 | 78.65 |
| SH003 | 盛大金磐 | 3室2厅1厨3卫 | 194.65 |
| 数据源2 | |||
|---|---|---|---|
| 房产编号 | 小区 | 房屋户型 | 建筑面积 |
| SH004 | 圣鑫苑 | 2室1厅1厨1卫 | 81.47 |
| SH005 | 塘南小区 | 2室1厅1厨2卫 | 46.76 |
| SH006 | 世茂滨江花园 | 3室2厅1厨3卫 | 237 |
# 代码实现
import pandas as pd
# 获取数据源,以excel为例
df1 = pd.read_excel("数据源1.xlsx")
df1 = pd.read_excel("数据源2.xlsx")
# 进行上下合并,axis=0 表示上下合并,
all_data = pd.concat((df1, df2), axis=0)
# 或者
# 使用append 进行数据的拼接 ---垂直拼接,即上下合并
# 直接将 df2拼接到df1的下面
all_data = df1.append(df2)
| 合并后的数据 | |||
|---|---|---|---|
| 房产编号 | 小区 | 房屋户型 | 建筑面积 |
| SH001 | 江临天下 | 4室2厅1厨2卫 | 165.73 |
| SH002 | 樱花路309弄 | 2室2厅1厨1卫 | 78.65 |
| SH003 | 盛大金磐 | 3室2厅1厨3卫 | 194.65 |
| SH004 | 圣鑫苑 | 2室1厅1厨1卫 | 81.47 |
| SH005 | 塘南小区 | 2室1厅1厨2卫 | 46.76 |
| SH006 | 世茂滨江花园 | 3室2厅1厨3卫 | 237 |
如果两个数据源中对应行的信息为同一个房产记录,可使用左右合并,将其合并为一个完整数据
| 数据源1 | ||||
|---|---|---|---|---|
| 房产编号 | 小区 | 房屋户型 | 建筑面积 | 户型结构 |
| SH001 | 江临天下 | 4室2厅1厨2卫 | 165.73 | 平层 |
| SH002 | 樱花路309弄 | 2室2厅1厨1卫 | 78.65 | 复式 |
| SH003 | 盛大金磐 | 3室2厅1厨3卫 | 194.65 | 平层 |
| 数据源2 | |||
|---|---|---|---|
| 房产编号 | 梯户比例 | 配备电梯 | 挂牌时间 |
| SH001 | 六梯六户 | 有 | 2018/5/18 |
| SH002 | 一梯两户 | 无 | 2018/6/24 |
| SH003 | 三梯三户 | 有 | 2019/3/17 |
import pandas as pd
# 获取数据源,以excel为例
df1 = pd.read_excel("数据源1.xlsx")
df1 = pd.read_excel("数据源2.xlsx")
# 进行上下合并,axis=1 表示左右合并,
all_data = pd.concat((df1, df2), axis=1)
| 合并后的数据 | |||||||
|---|---|---|---|---|---|---|---|
| 房产编号 | 小区 | 房屋户型 | 建筑面积 | 户型结构 | 梯户比例 | 配备电梯 | 挂牌时间 |
| SH001 | 江临天下 | 4室2厅1厨2卫 | 165.73 | 平层 | 六梯六户 | 有 | 2018/5/18 |
| SH002 | 樱花路309弄 | 2室2厅1厨1卫 | 78.65 | 复式 | 一梯两户 | 无 | 2018/6/24 |
| SH003 | 盛大金磐 | 3室2厅1厨3卫 | 194.65 | 平层 | 三梯三户 | 有 | 2019/3/17 |
如果数据源1和数据源2不能按照行号或行索引直接进行左右合并。比如:合并时必须考虑某些属性信息作为关键信息,此时可以使用主键合并。
如果数据源1和数据源2的关键属性信息名字一致,关键属性信息可以有一个也可以多个,直接在on中指定即可。
| 数据源1 | |||
|---|---|---|---|
| 房产编号 | 小区 | 房屋户型 | 建筑面积 |
| SH001 | 江临天下 | 4室2厅1厨2卫 | 165.73 |
| SH002 | 樱花路309弄 | 2室2厅1厨1卫 | 78.65 |
| SH003 | 盛大金磐 | 3室2厅1厨3卫 | 194.65 |
| 数据源2 | ||||
|---|---|---|---|---|
| 房产编号 | 户型结构 | 梯户比例 | 配备电梯 | 挂牌时间 |
| SH002 | 平层 | 六梯六户 | 有 | 2018/5/18 |
| SH003 | 复式 | 一梯两户 | 无 | 2018/6/24 |
| SH004 | 平层 | 三梯三户 | 有 | 2019/3/17 |
# 使用merge实现主键合并
all_data = pd.merge(df1,
df2,
how="inner", # 指定连接方式
on="房产编号" # 指定主键
)
| 合并后 | |||||||
|---|---|---|---|---|---|---|---|
| 房产编号 | 小区 | 房屋户型 | 建筑面积 | 户型结构 | 梯户比例 | 配备电梯 | 挂牌时间 |
| SH002 | 樱花路309弄 | 2室2厅1厨1卫 | 78.65 | 平层 | 六梯六户 | 有 | 2018/5/18 |
| SH003 | 盛大金磐 | 3室2厅1厨3卫 | 194.65 | 复式 | 一梯两户 | 无 | 2018/6/24 |
属性名称不一致,但意义相同
由于命名不规范或者行业内部不统一,对于同一属性的名称表示。数据源1称为“房产编号”,数据源2称为“house id”,但是意义相同,都为房产的编号。因此在数据集成时可以考虑将其中一个重命名再进行合并,或者直接利用主键合并,并指定左主键和右主键进行集成,然后再删除其中一个。
| 数据源1 | |||
|---|---|---|---|
| 房产编号 | 小区 | 房屋户型 | 建筑面积 |
| SH001 | 江临天下 | 4室2厅1厨2卫 | 165.73 |
| SH002 | 樱花路309弄 | 2室2厅1厨1卫 | 78.65 |
| SH003 | 盛大金磐 | 3室2厅1厨3卫 | 194.65 |
| 数据源2 | ||||
|---|---|---|---|---|
| house_id | 户型结构 | 梯户比例 | 配备电梯 | 挂牌时间 |
| SH002 | 平层 | 六梯六户 | 有 | 2018/5/18 |
| SH003 | 复式 | 一梯两户 | 无 | 2018/6/24 |
| SH004 | 平层 | 三梯三户 | 有 | 2019/3/17 |
# 使用merge实现主键合并
all_data = pd.merge(df1,
df2,
how="inner", # 指定连接方式
left_on="房产编号", # 指定左主键
right_on="house_id", # 指定右主键
)
| 合并后数据 | ||||||||
|---|---|---|---|---|---|---|---|---|
| 房产编号 | house_id | 小区 | 房屋户型 | 建筑面积 | 户型结构 | 梯户比例 | 配备电梯 | 挂牌时间 |
| SH002 | SH002 | 樱花路309弄 | 2室2厅1厨1卫 | 78.65 | 平层 | 六梯六户 | 有 | 2018/5/18 |
| SH003 | SH003 | 盛大金磐 | 3室2厅1厨3卫 | 194.65 | 复式 | 一梯两户 | 无 | 2018/6/24 |
但是如果主键名称一致,但意义不同。比如数据源1和数据源2中都存在房产价格,但是一个为包含交易税的价格,一个为不包含交易税的价格。因此在数据集成时,我们需要将其中一个重命名,再继续合并。
如果两个数据源都不太完整,但是行列信息是一致,可以借助重叠合并将两个数据源合并为相对完整的一个数据。
| 数据源1 | ||||
|---|---|---|---|---|
| 房产编号 | 户型结构 | 梯户比例 | 配备电梯 | 挂牌时间 |
| SH002 | 平层 | 无 | 2018/5/18 | |
| SH003 | 复式 | 2018/6/24 | ||
| SH004 | 平层 | 2019/3/17 |
| 数据源2 | ||||
|---|---|---|---|---|
| 房产编号 | 户型结构 | 梯户比例 | 配备电梯 | 挂牌时间 |
| SH002 | 六梯六户 | 有 | ||
| SH003 | 一梯两户 | 无 | ||
| SH004 | 三梯三户 | 有 |
# df1是主表,用df2中内容,覆盖df1中的内容
# 如果主表中有内容,就跳过。 如果主表中为空,用df2对应位置的非空值进行覆盖
# 通常选择 数据相对准确和完整的DF 作为主表
res = df1.combine_first(df1)
| 合并后数据 | ||||
|---|---|---|---|---|
| 房产编号 | 户型结构 | 梯户比例 | 配备电梯 | 挂牌时间 |
| SH002 | 平层 | 六梯六户 | 无 | 2018/5/18 |
| SH003 | 复式 | 一梯两户 | 无 | 2018/6/24 |
| SH004 | 平层 | 三梯三户 | 有 | 2019/3/17 |
(二) 数据清洗
数据清洗(data cleaning) 的主要是通过填补缺失值、删除重复值,平滑或删除离群点,并解决数据的不一致性来“清理“数据来提升数据质量的过程。如果用户认为数据时脏乱的,他们不太会相信基于这些数据的挖掘结果,即输出的结果是不可靠的。如若希望尽可能小让缺失值、噪声等脏数据影响数据挖掘的结果,更有效的方法应是提高数据质量
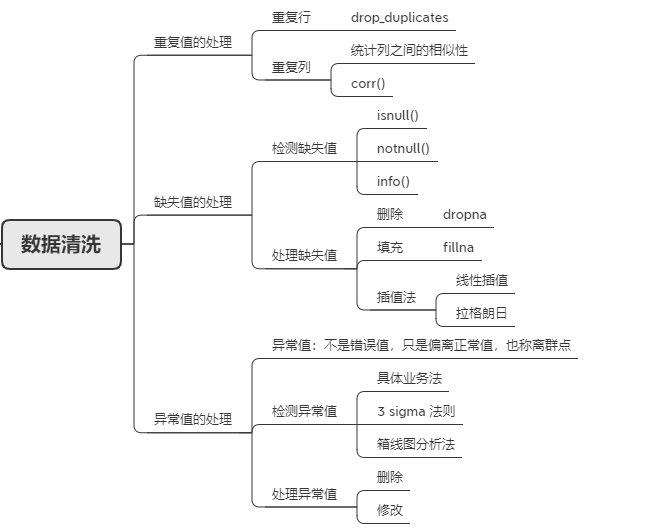
由于现实世界中,获取信息和数据的过程中,由于采集、编码误差等各类原因导致数据丢失和空缺。针对这些缺失值的处理方法,需要给予适当的处理。主要是基于信息的分布特性和信息的重要性采用不同的方法。
在对缺失值进行处理,首先应该检测是否存在缺失值,哪些特征属性有缺失值、以及缺失的程度。通常可以使用如下方式检测缺失值:
识别缺失值的方法isnull以及识别非缺失值的方法notnull,这两种方法在使用时返回的都是布尔值True和False。结合sum函数和isnull、notnull函数,可以检测数据中缺失值的分布以及数据中一共含有多少缺失值。
整例删除(casewise deletion)是剔除含有缺失值的样本。由于很多问卷都可能存在缺失值,这种做法的结果可能导致有效样本量大大减少,无法充分利用已经收集到的数据。因此,只适合关键变量缺失,或者含有无效值或缺失值的样本比重很小的情况。
变量删除(variable deletion)。如果某一变量的无效值和缺失值很多,而且该变量对于所研究的问题不是特别重要,则可以考虑将该变量删除。这种做法减少了供分析用的变量数目,但没有改变样本量。
成对删除(pairwise deletion)是用一个特殊码(通常是9、99、999等)代表无效值和缺失值,同时保留数据集中的全部变量和样本。但是,在具体计算时只采用有完整答案的样本,因而不同的分析因涉及的变量不同,其有效样本量也会有所不同。这是一种保守的处理方法,最大限度地保留了数据集中的可用信息。
填充法
统计量填充
填充法是指用一个特定的值替换/填充缺失值。特征可分为数值型和类别型,两者出现缺失值时的处理方法也是不同的。缺失值所在特征为数值型时,通常利用其均值、中位数和众数等描述其集中趋势的统计量来代替缺失值。缺失值所在特征为类别型时,则选择使用众数来替换缺失值。
定量填充
使用一定固定的值进行填充,常见用-9999进行替代缺失值
插值法
删除法简单易行,但是会引起数据结构变动,样本减少;替换法使用难度较低,但是会影响数据的标准差,导致信息量变动。在面对数据缺失问题时,除了这两种方法之外,还有一种常用的方法―插值法。例如,某一产品的拥有情况可能与家庭收入有关,可以根据调查对象的家庭收入推算拥有这一产品的可能性。
采用不同的处理方法可能对分析结果产生影响,尤其是当缺失值的出现并非随机且变量之间明显相关时。因此,在数据获取时中应当尽量避免出现无效值和缺失值,保证数据的完整性
异常值是数据分布的常态,处于特定分布区域或范围之外的数据通常被定义为异常或噪声。异常分为两种:“伪异常”,由于特定的业务运营动作产生,是正常反应业务的状态,而不是数据本身的异常;“真异常”,不是由于特定的业务运营动作产生,而是数据本身分布异常,即离群点。
异常值的存在对数据分析十分危险,如果计算分析过程的数据有异常值,那么会对结果会产生不良影响,从而导致分析结果产生偏差乃至错误。
比如在分析银行欺诈案例时,核心就是要发现异常值,这个时候异常值对我们是有用的。再比如,在统计某个城市的平均收入的时候,有人月收入是好几个亿,这个时候这个人就是一个异常值,这个异常值会拉高城市的整体平均收入,因此可能会得到一个不真实的分析结果。
主要有以下检测离群点的方法:具体业务法、3σ原则和箱线图分析
根据你对业务的理解,然后对每一个指标设定一个合理的范围,一旦超过这个范围,则认为是异常值。比如收入,一般来说都是正数,如果出现小于0,则认为是异常值;再比如年龄,正常的年龄可能在100以内,如果出现年龄是好几百的,那么也认为是异常值。
def fun(val):
# 如果在合理范围,返回True,否则返回False
low = 50
high = 220
return (val >= low) & (val <= high)
3σ原则又称为拉依达法则。该法则就是先假设一组检测数据只含有随机误差,对原始数据进行计算处理得到标准差,然后按一定的概率确定一个区间,认为误差超过这个区间的就属于异常值。这种判别处理方法仅适用于对正态或近似正态分布的样本数据进行处理,如下表所示,其中σ代表标准差,μ代表均值,x=μ为图形的对称轴。
| 数值分布 | 在数据中的占比 |
|---|---|
| $(\mu-\sigma, \mu+\sigma)$ | 0.6827 |
| $(\mu-2\sigma, \mu+2\sigma)$ | 0.9545 |
| $(\mu-3\sigma, \mu+3\sigma)$ | 0.9973 |
数据的数值分布几乎全部集中在区间(μ-3σ,μ+3σ)内,超出这个范围的数据仅占不到0.3%。故根据小概率原理,可以认为超出3σ的部分数据为异常数据。
def three_sigma(data):
"""
进行3sigma 异常值剔除
:param data: 原数据--series
:return: bool数组
"""
# 上限
up = data.mean() + 3 * data.std()
# 下限
low = data.mean() - 3 * data.std()
# 在上限与下限之间的数据 是正常的
bool_index = (data < up) & (data > low)
return bool_index
箱型图提供了识别异常值的一个标准,即异常值通常被定义为小于QL-1.5IQR或大于QU+1.5IQR的值。
QL称为下四分位数,表示全部观察值中有四分之一的数据取值比它小。
QU称为上四分位数,表示全部观察值中有四分之一的数据取值比它大。
IQR称为四分位数间距,是上四分位数QU与下四分位数QL之差,其间包含了全部观察值的一半。
箱线图依据实际数据绘制,真实、直观地表现出了数据分布的本来面貌,且没有对数据做任何限制性要求,其判断异常值的标准以四分位数和四分位数间距为基础。四分位数给出了数据分布的中心、散布和形状的某种指示,具有一定的鲁棒性,即25%的数据可以变得任意远而不会很大地扰动四分位数,所以异常值通常不能对这个标准施加影响。鉴于此,箱线图识别异常值的结果比较客观,因此在识别异常值方面具有一定的优越性。
def boxplot_analysis(val):
ql, qu = val.quantile(q=[0.25, 0.75])
IQR = qu - ql
low = ql - 1.5 * IQR
high = qu + 1.5 * IQR
return (val >= low) & (val <= high)
常会发现数据中会出现重复的数据,而这些重复数据是没有什么用处的,并且会影响预测内容准确性,需要我们删除这些重复的值,所以在数据处理时,删除重复值是很重要。重复分为特征重复和记录重复。
特征重复,即不同属性表示的是同一个数据信息。比如对于人的体重信息,数据源中分别以斤和公斤为单位记录每个人的体重。在房产数据中,如果同时存在房子的室内面积和房子的建筑面积。虽然两个特征不完成一致,但是具有高度的相关性。
对于特征重复的删除,可以结合相关的数学和统计学知识,去除连续型特征重复可以利用特征间的相似度将两个相似度为1或者接近1的特征去除一个。
记录重复,也称为样本重复,即某几个记录的一个或者多个特征值完全相同。在房产领域可能存在多个工作人员同时将一个房产进行挂牌登记,如果每个工作人员收集的信息不完全一致,但是关键的小区名称、楼层、单元号、户型完全一致。因此如果某几个记录的关键特征完全一致,就可以认定了记录重复,并且进行删除处理。
对于记录重复,在删除时,可以选择是保留第一个或者最后一个
# 如果两行内容完全一致 ==== 属于重复行
# 如果两行中关键内容(某些列内容)一致 === 重复行
# keep 多行重复,保留哪一行,默认第一行
# keep参数 first(保留第一行)、last(保留最后一行)、False(删除所有重复的)
data.drop_duplicates(
# subset 如果不指定列名称,默认对所有列
# subset=["小区名称", "楼层","单元号","户型"],
# keep="first",
inplace=True
)
(三) 数据变换
在数据分析之前,我们通常需要先将数据标准化(normalization),利用标准化后的数据进行数据分析。数据标准化也就是统计数据的指数化。数据标准化处理主要包括数据同趋化处理和无量纲化处理两个方面。数据同趋化处理主要解决不同性质数据问题,对不同性质指标直接加总不能正确反映不同作用力的综合结果,须先考虑改变逆指标数据性质,使所有指标对测评方案的作用力同趋化,再加总才能得出正确结果。数据无量纲化处理主要解决数据的可比性。数据标准化的方法有很多种,常用的有“最小―最大标准化”、“Z-score标准化”和“按小数定标标准化”等。经过上述标准化处理,原始数据均转换为无量纲化指标测评值,即各指标值都处于同一个数量级别上,可以进行综合测评分析。
(1) Min-max 标准化
min-max标准化方法是对原始数据进行线性变换。设minA和maxA分别为属性A的最小值和最大值,将A的一个原始值x通过min-max标准化映射成在区间[0,1]中的值x',其公式为:
新数据=(原数据-最小值)/(最大值-最小值)
(2) z-score 标准化
这种方法基于原始数据的均值(mean)和标准差(standard deviation)进行数据的标准化。将A的原始值x使用z-score标准化到x'。z-score标准化方法适用于属性A的最大值和最小值未知的情况,或有超出取值范围的离群数据的情况。
新数据=(原数据-均值)/标准差
(3) Decimal scaling小数定标标准化
这种方法通过移动数据的小数点位置来进行标准化。小数点移动多少位取决于属性A的取值中的最大绝对值。将属性A的原始值x使用decimal scaling标准化到x'的计算方法是:
x'=x/(10^j)
其中,j是满足条件的最小整数。
标准化会对原始数据做出改变,因此需要保存所使用的标准化方法的参数,以便对后续的数据进行统一的标准化。
某些模型算法,要求数据是离散的,此时就需要将连续型特征(数值型)变换成离散型特征(类别型)。
连续特征的离散化就是在数据的取值范围内设定若干个离散的划分点,将取值范围划分为一些离散化的区间,最后用不同的符号或整数值代表落在每个子区间中的数据值。
因此离散化涉及两个子任务,即确定分类数以及如何将连续型数据映射到这些类别型数据上。
| 数据源1 | |
|---|---|
| 编号 | 均价 |
| SH001 | 85078 |
| SH002 | 70000 |
| SH003 | 30000 |
new_data = pd.cut(house["均价"], bins=[0, 20000, 30000, 50000, 70000, 90000, 100000],
include_lowest=True)
| 数据源1 | |
|---|---|
| 编号 | 均价 |
| SH001 | [70000, 90000) |
| SH002 | [70000, 90000) |
| SH003 | [30000,50000) |
数据分析模型中有相当一部分的算法模型都要求输入的特征为数值型,但实际数据中特征的类型不一定只有数值型,还会存在相当一部分的类别型,这部分的特征需要经过哑变量处理才可以放入模型之中。
| 数据源1 | |
|---|---|
| 编号 | 区 |
| SH001 | 浦东新区 |
| SH002 | 黄浦区 |
| SH003 | 浦东新区 |
res_city = pd.get_dummies(
data=df['区'],
prefix='区', # 前缀
prefix_sep='_', # 分隔符
)
| 数据源1 | ||
|---|---|---|
| 编号 | 区_浦东新区 | 区_黄浦区 |
| SH001 | 1 | 0 |
| SH002 | 0 | 1 |
| SH003 | 1 | 0 |
(四) 数据规约
(1)样本归约 样本都是已知的,通常数目很大,质量或高或低,或者有或者没有关于实际问题的先验知识。 样本归约就是从数据集中选出一个有代表性的样本的子集。子集大小的确定要考虑计算成本、存储要求、估计量的精度以及其它一些与算法和数据特性有关的因素。 初始数据集中最大和最关键的维度数就是样本的数目,也就是数据表中的记录数。数据挖掘处理的初始数据集描述了一个极大的总体,对数据的分析只基于样本的一个子集。获得数据的子集后,用它来提供整个数据集的一些信息,这个子集通常叫做估计量,它的质量依赖于所选子集中的元素。取样过程总会造成取样误差,取样误差对所有的方法和策略来讲都是固有的、不可避免的,当子集的规模变大时,取样误差一般会降低。一个完整的数据集在理论上是不存在取样误差的。与针对整个数据集的数据挖掘比较起来,样本归约具有以下一个或多个优点:减少成本、速度更快、范围更广,有时甚至能获得更高的精度。
(2)特征规约
特征归约是从原有的特征中删除不重要或不相关的特征,或者通过对特征进行重组来减少特征的个数。其原则是在保留、甚至提高原有判别能力的同时减少特征向量的维度。特征归约算法的输入是一组特征,输出是它的一个子集。在领域知识缺乏的情况下进行特征归约时一般包括3个步骤: a. 搜索过程:在特征空间中搜索特征子集,每个子集称为一个状态由选中的特征构成。 b. 评估过程:输入一个状态,通过评估函数或预先设定的阈值输出一个评估值搜索算法的目的是使评估值达到最优。 c. 分类过程:使用最终的特征集完成最后的算法。 特征归约处理的效果: a. 更少的数据,提高挖掘效率 b. 更高的数据挖掘处理精度 c. 简单的数据挖掘处理结果 d. 更少的特征。
Copyright©1999- 北京中公教育科技有限公司 .All Rights Reserved 京ICP备10218183号-88
京ICP证161188号  京公网安备11010802020723号
京公网安备11010802020723号  投诉建议:400-650-7353
投诉建议:400-650-7353










 视频教程
视频教程

 项目简介
项目简介

 数据处理
数据处理

 数据分析和可视化
数据分析和可视化
 (一) 数据集成
(一) 数据集成 

